Pour réussir à ingérer les données en flux continu et les délivrer efficacement dans le Data Lake, les outils d’ingestion s’appuient sur deux éléments particuliers : une structure de données particulière appelée le Log ou bus d’événements et un système de messagerie Publish/Subscribe.
Kafka et le Data Lake à la rescousse du streaming
Le Data Lake/Data Warehouse est toujours utilisé en support au stockage de données à la fin de la chaîne en streaming, mais l’ingestion se fait à travers un bus d’événements et un système de messagerie Publish/Subscribe.
Cette session de cours vidéo porte sur le fonctionnement général d’Apache Kafka, le système de messagerie Publish-Subscribe distribué le plus utilisé du marché.
Contexte et intérêt de Kafka en Big Data
En réalité, pour comprendre Kafka, il faut comprendre de Streaming et pour véritablement comprendre le concept de Streaming, il faut comprendre le concept d’objets connectés.
Les objets connectés ou Internet des objets (IoT – Internet of Things en anglais) représentent l’extension d’Internet à nos vies quotidiennes. Ils génèrent des données en streaming et dans la plupart de ses problématiques, nécessitent que les données soient traitées en temps réel.
Les modèles que vous connaissez tels que les modèles de calcul Batch ne sont pas adaptés aux problématiques temps réel que soulève l’IoT. Même les modèles de calcul interactif ne sont pas adaptés pour faire du traitement continu en temps réel.
A la différence des données opérationnelles produites par les systèmes opérationnels d’une entreprise comme la finance, le marketing, qui même lorsqu’elles sont produites en streaming (ou au fil-de-l’eau) peuvent être historisées pour un traitement ultérieur, les données produites en streaming dans le cadre des phénomènes comme l’IoT ou Internet se périment (ou ne sont plus valides) dans les instants qui suivent leur création et exigent donc un traitement immédiat.
En dehors des objets connectés, les problématiques métier comme la lutte contre la fraude, l’analyse des données de réseau sociaux, la géolocalisation, exigent des temps de réponse très faibles, quasiment de l’ordre de moins d’une seconde.
Pour résoudre cette problématique dans un contexte Big Data, il faut être capable d’ingérer les données en temps réel. Kafka est un système de messagerie Publish-Subscribe distribué, scalable et tolérant aux pannes. A la différence de ses confrères RabbitMQ ou ActiveMQ, il combine les fonctionnalités d’agrégation, de séquencement du Log, et les fonctionnalités du système de messagerie Publish-Subscribe pour le routage des données entre plusieurs sources opérationnelles et plusieurs applications abonnées. De plus, pour les besoins de haute performance il est scalable, car il tourne sur un cluster et offre un haut débit pour le transfert de données. En d’autres termes, Kafka est un système distribué, scalable de messagerie Publish-Subscribe qui s’appuie sur le Log.
Kafka en lui-même ne fournit pas les fonctionnalités de traitement de données Streaming, mais les consommateurs des services de souscription de Kafka peuvent rajouter ces fonctionnalités. C’est le cas avec Kafka Streams, Spark Streaming ou Apache Flink, qui sont des outils spécialisés uniquement sur le traitement de données streaming.
LinkedIn combine Apache Kafka + Apache Samza pour résoudre ses challenges de streaming. En 2009, lors de sa mise en production chez LinkedIn, Kafka gérait l’ingestion de plus de 10 milliards d’écriture de messages chaque jour, avec un pic soutenu de 172 000 messages par seconde, avec une douzaine de systèmes souscripteurs auxquels il délivrait plus de 55 milliards de messages chaque jour.
Architecture d’Apache Kafka
Depuis 2011, Kafka fait partie des projets de la fondation Apache et depuis 2012, en est un projet prioritaire. Kafka fonctionne exactement selon le même principe qu’un Log, c’est-à-dire qu’il enregistre les messages dans une structure persistante et permet à des souscripteurs de lire les données qui y sont stockées et de mettre à jour leur propres bases de données grâce à ces données. En informatique, cette technique est qualifié de Write-Ahead Logging (WAL – persistance anticipée des écritures de données).
Le Log (différent du bus de données) est une structure Write-Ahead, c’est pourquoi il est appelé dans certains cas Log Write-Ahead. Dans un système de gestion de bases de données WAL, toutes les modifications de données sont écrites dans un Log avant d’être appliquées à la base de données. Pour illustrer ce principe, prenons l’exemple suivant : supposons que la machine sur laquelle un programme en cours d’exécution d’une opération tombe subitement en panne ; lors du redémarrage de la machine, ce programme voudra vérifier l’état de l’opération qu’il exécutait avant la panne, pour savoir s’il doit relancer l’opération ou pas. Si un Log Write-Ahead est utilisé, alors cette information (l’état du programme avant la panne, et même les instructions du programme et les résultats du traitement) y est disponible. Sur la base de cette information, le programme peut alors décider de relancer l’opération, ou de l’abandonner.
Le Log Write-Ahead permet aux mises à jour d’une base de données d’être faites sans utiliser une structure persistante de données telles qu’une table ou un fichier. La figure suivante illustre l’architecture et le fonctionnement de Kafka.
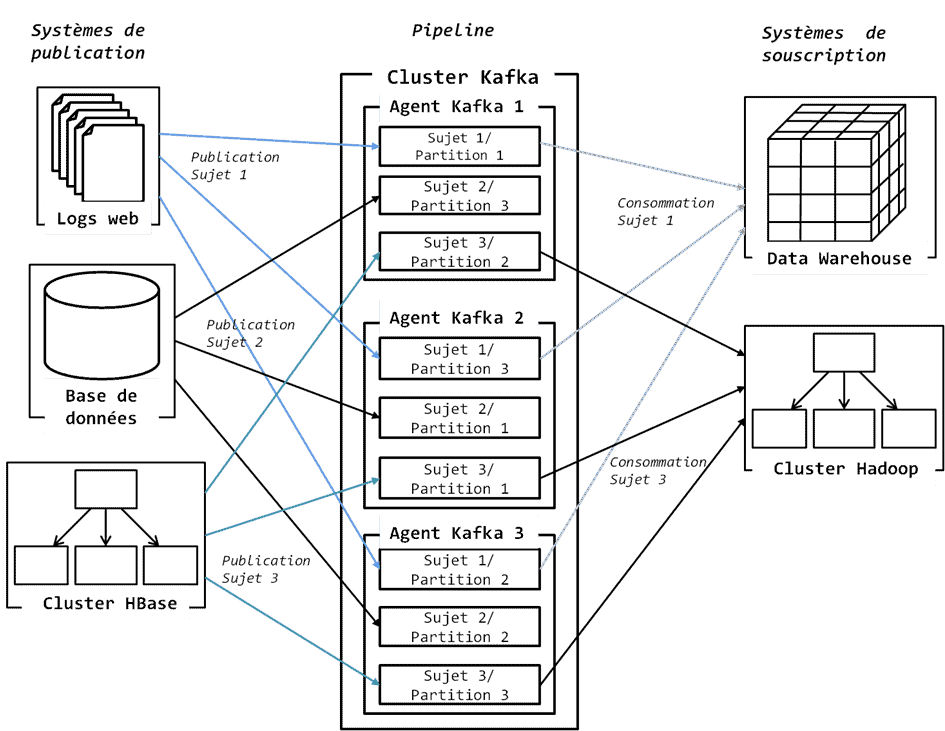
Parler profondément de Kafka exige que nous rentrions dans des notions complexes telles que les notions de Log, WAL, système de message Publish/Subscribe, broadcastening… qui sont largement hors des objectifs de cet article. Si vous souhaitez aller plus loin dans la façon dont Kafka peut être utilisé pour construire un Data Lake et gérer les problématiques de données générées au fil de l’eau, nous vous suggérons de vous inscrire gratuitement à la formation ci-bas.


