I. Introduction
Dans le tutoriel précédent le SQL dans Hadoop – Hive & Pig, nous vous avons montré comment exécuter le SQL sur Hadoop via un langage d’abstraction similaire et conforme à la norme ANSI 92 du SQL. Dans ce tutoriel, nous vous apprendrons à exécuter du SQL directement et nativement dans Hadoop.
Hadoop est en train de gagner du terrain dans les entreprises, celles-ci utilisent de plus en plus HDFS (Hadoop Distributed File System) comme répertoire de stockage central pour certaines de leurs données ; notamment celles provenant de la comptabilité, du marketing, de la finance, des ressources humaines, des médias sociaux, d’Internet, de capteurs, et somme toute de diverses applications… Au même moment, la majorité des outils utilisés par celles-ci tels que SAP, Oracle, SAS, Tableau, QlikView Excel, et leurs traditionnelles bases relationnelles s’appuient toutes sur le SQL. C’est l’une des raisons majeures qui a provoqué le développement des offres SQL sur Hadoop ces dernières années. Facebook a été le premier sur le marché à offrir une solution SQL sur Hadoop, Hive.
L’approche utilisée par Hive consiste à transformer et compiler en arrière-plan les requêtes HiveQL que les utilisateurs écrivent en série de jobs MapReduce. Plus tard, d’autres acteurs à l’instar de Yahoo ! sont entrés sur le marché et ont offert des solutions similaires à Hive. Les plus significatifs d’entre elles étant Pig et Cascading.
Le problème avec l’approche adoptée par ces solutions (Hive, Pig, Cascading…) est qu’à mesure que les besoins des utilisateurs ont évolué et que les exigences du numérique se sont accrues, le temps de latence généré lors de la transformation des requêtes en jobs MapReduce est devenu inacceptable. Pour résoudre ce problème, la majorité des éditeurs ont décidé de développer des moteurs SQL natifs, c’est-à-dire des moteurs de calcul massivement parallèles qui exécutent nativement le SQL directement sur le HDFS sans passer par le MapReduce.
Vous vous demandez peut-être comment cela est possible. En fait, le concept de moteur SQL massivement parallèle n’est pas nouveau. Outre le fait que les grands SGBDR savent traiter une même requête sur plusieurs threads (Oracle, SQL Server, IBM DB2…), certains systèmes de gestion de bases de données relationnelles tels que GreenPlum, Teradata, PostgreSQL, Informix XPS, IBM DB2 UDB, SQL Server Parallel DWH, ou Sybase IQ12-Multiplex distribuent les bases de données sur un ensemble d’ordinateurs connectés à un réseau LAN et exécutent des requêtes SQL de façon concurrente (parallèle) et simultanée sur ces machines. Parce qu’ils sont capables d’exécuter du SQL sur des architectures distribuées, ces systèmes ont été qualifiés de Systèmes Parallèles de Gestion de Bases de données relationnelles ou de Bases de données à architecture MPP (Massively Parallel Processing). Couramment, on les appelle les Bases de Données Parallèles (Parallel Data Base ou Parallel DataWarehouse) ou Massively Parallel Processing Databases (MPP DB).
Étant donné qu’un cluster Hadoop est par définition Shared-Nothing (et donc MPP), tous les moteurs SQL natifs Hadoop se sont simplement inspirés des principes de ces bases de données parallèles.
Dans ce tutoriel, vous allez apprendre d’une part les principes de fonctionnement des moteurs SQL sur Hadoop, et comprendre comment fonctionne l’un des moteurs SQL sur Hadoop natifs les plus connus, à savoir Impala. Et d’autre part, vous allez apprendre à écrire des requêtes SQL qui s’exécutent sur des moteurs MPP.
Étant donné que les principes de fonctionnement de tous ces moteurs sont sensiblement les mêmes, la connaissance d’Impala vous permettra de les transposer à d’autres moteurs SQL Hadoop facilement. Cependant, pour que vous ayez la meilleure compréhension possible des moteurs SQL sur Hadoop, il vous faut obligatoirement comprendre le fonctionnement des bases de données parallèles (Massively Parallel Database). En définitive, tout commence par là…
II. Les bases de données distribuées
Dans le chapitre 2 de l’ouvrage « Hadoop – Devenez opérationnel dans le monde du Big Data », nous décrivons les différentes architectures de calcul qui sont à la base de tout traitement informatique. Parmi ces architectures, citons l’architecture client-serveur. À titre de rappel, une architecture client-serveur est une architecture informatique dans laquelle un processus (un ordinateur, une application informatique) appelé serveur agit comme fournisseur de ressources pour d’autres processus appelés clients, qui effectuent des demandes (requêtes). Les ressources fournies par le processus serveur peuvent être le résultat d’une requête SQL (un « data set »), le lancement d’une impression papier, l’affichage d’une page Web, etc. Le processus serveur et les processus clients s’exécutent généralement sur des ordinateurs différents reliés au même réseau. Ici, les tâches qui sont centralisées vers le serveur sont délocalisées et réparties à plusieurs niveaux d’entrée du système informatique (PC, ordinateur portable, tablette, etc.). Le but est de décharger l’ordinateur central du plus grand nombre de fonctions possible. Ainsi, dans cette architecture, plusieurs niveaux de délocalisation des tâches sont possibles : client-serveur à deux niveaux (en anglais two-tiers), client-serveur à trois niveaux (three-tiers), etc. La figure suivante illustre une architecture client-serveur à trois niveaux classique utilisée dans la majorité des applications web traditionnelles.
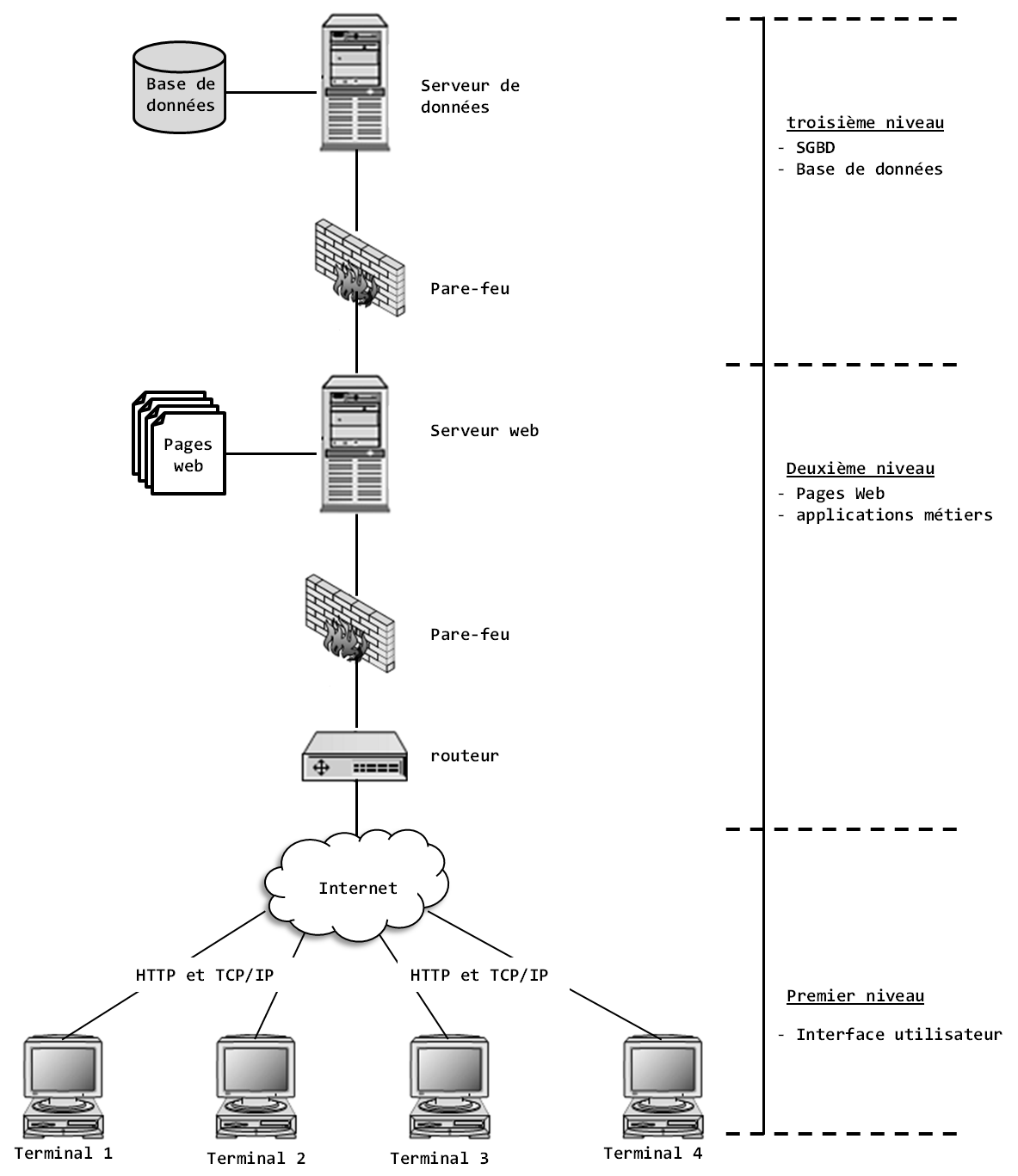
La présentation des architectures client-serveur n’est pas du cadre de ce tutoriel, mais permet de montrer que dans les architectures client-serveur, la seule forme de distribution possible consiste à répartir les charges de calcul entre une machine serveur et plusieurs machines clientes. Elles restent donc quelque part une approche centralisée, car seul, le serveur centralise les tâches d’administration et répond à toutes les demandes des utilisateurs. Or, pour faire du traitement massivement parallèle, il faut utiliser un cluster et choisir entre trois types d’architectures : les architectures Shared-Disk, les architectures Shared-Memory et les architectures Shared-Nothing. À titre d’exemple, en mi-décembre 1999, l’entreprise Deutsche Telecom avait annoncé que son DataWarehouse stockait 100 téraoctets de données (soit 102 400 Go). La question qui se posait alors était : comment faire pour qu’un SGBDR qui héberge un DataWarehouse d’une telle volumétrie réponde efficacement aux requêtes SQL des milliers d’employés de l’entreprise ?
II-A. Architecture des bases de données distribuées
Avec la baisse des coûts des ordinateurs, l’augmentation de la puissance de calcul et le développement du réseau, l’approche utilisée pour résoudre un problème comme celui de Deutsche Telecom consiste à :
- utiliser un cluster de machines à architecture Shared-Memory ou Shared-Nothing ;
- répliquer dans chaque nœud du cluster une structure de base de données identique et vide ;
- partitionner les données de la base de données ;
- distribuer les partitions à tous les nœuds contenant la réplique de la structure de la base de données.
Avec ce mode de fonctionnement, les requêtes SQL qui arrivent dans le système sont parallélisées et exécutées de façon concurrente, par des processus indépendants appliqués aux différents nœuds contenant les partitions de la base de données. Comme chaque nœud contient une partie de la base de données, il s’ensuit que la charge de calcul (les 100 To par exemple) est répartie à travers tout le cluster et que les processus de la requête s’exécutent directement in situ (en local) dans le ou les nœuds considérés, une même requête pouvant toucher différentes partitions.
C’est cela le principe des bases de données parallèles.
Pour des besoins de scalabilité, les SGBDR parallèles de DataWarehouse privilégient l’architecture Shared-Nothing. C’est d’ailleurs pourquoi on les appelle MPP Database (Massively Parallel Processing database) pour faire référence au fait que dans une architecture Shared-Nothing, chaque nœud constitue un processeur indépendant, par conséquent l’ensemble des nœuds forme un cluster de processeurs.
Dans les bases de données parallèles, la structure de la base de données est répliquée à l’identique entre tous les nœuds d’un cluster Shared-Nothing et les données sont distribuées sur les différentes partitions à travers ces nœuds, de sorte que chaque nœud héberge une partie de la base de données. De plus, toutes les communications dans le cluster se font via le réseau (LAN ou fibre optique).
Par exemple, si la base de données contient une table clients et que le cluster est constitué de 50 nœuds, alors il y aura 50 instances de la table clients, et chacune aura une partition différente des données de la table, un même client n’étant stocké que dans une seule partition, un seul nœud du cluster. Pour exécuter une requête SQL sur cette table, chaque nœud va simultanément exécuter la requête sur sa base de données locale. Lorsque l’exécution de la requête sera terminée dans tous les nœuds, une phase de rassemblement va se déclencher dans le nœud central du cluster et va agréger les résultats de la requête.
Le problème majeur avec l’approche de base de données parallèle est la localisation des données. Lorsque la base de données est installée dans une architecture Shared-Memory, le stockage de la base est centralisé et chaque nœud possède en mémoire une copie de la base. En revanche, dans une architecture Shared-Nothing, chaque nœud possède sa propre mémoire et son propre stockage, par conséquent la base de données doit être partitionnée et distribuée pour chacun des nœuds du cluster.
Dans cette dernière architecture, chaque nœud ne peut donc accéder qu’à sa propre partition de base de données. Par conséquent, la façon dont la base de données est partitionnée a un impact direct sur le niveau de complexité des programmes qui vont exploiter cette base de données, spécialement pour les opérations de jointure. En effet, l’architecture Shared-Nothing, impose que les tâches ne soient pas dépendantes de plusieurs nœuds en vertu de l’exigence de parallélisme du traitement des requêtes. Autrement dit, chaque partie de la requête s’exécute sur un nœud sans jamais interagir avec un processus concurrent de la même requête.
Le partitionnement de la base de données doit donc se faire de façon à ce que les partitions soient les plus indépendantes possible. À quelques exceptions près, tous les systèmes de bases de données parallèles utilisent le partitionnement horizontal pour diviser les tables de la base de données originale. Celui-ci consiste à diviser une table par intervalles de lignes, sans chevauchement et sans « trou ». Il se différencie du partitionnement vertical qui consiste à diviser une table par colonne, la clé servant de référence commune pour retrouver les données d’une même ligne. Le partitionnement vertical est plus approprié lorsque la problématique à traiter implique de nombreuses jointures, mais très coûteux quand il s’agit de traitement sur lignes. Avec le partitionnement horizontal, comme la table est partitionnée en lignes et que les lignes sont complètement indépendantes les unes des autres, les partitions peuvent être traitées de façon parallèle.
Une fois obtenu les l partitions de lignes d’une même table, la question se pose de l’accès aux différents nœuds. Autrement dit, comment le système répartit-il les partitions sur l’ensemble des nœuds du cluster ? Pour résoudre ce problème, il existe principalement trois méthodes de répartition des données : l’affectation par intervalle, l’affectation round-robin et l’affectation par hachage (hashing).
- Dans l’affectation par intervalle, une ou plusieurs colonnes de la table sont spécifiées comme clé de partitionnement. Généralement c’est la clé primaire, ou une clé alternative non nulle, de la table qui est utilisée comme clé de partitionnement. Chaque nœud reçoit alors un intervalle de valeurs de la clé. Cette méthode possède l’avantage que la clé agit comme un index, ce qu’elle est naturellement. Mais il faut s’assurer que la distribution des valeurs de la clé assure une répartition relativement équilibrée des lignes entre les nœuds et le reste au fil du temps, et que les valeurs de cette clé soient immuables.
- Pour résoudre le problème de non-uniformité de la clé et le déséquilibre que cela peut engendrer dans la répartition des charges de calcul, l’affection round-robin répartit les lignes de la table à raison d’une ligne par nœud de manière circulaire. Le premier nœud reçoit la ligne 1, le second la 2e, etc., et une fois atteint le dernier nœud, on cycle la distribution des lignes en revenant au premier nœud, tout cela de manière indépendante de la valeur de la clé. On a alors l’assurance que les lignes seront aussi distribuées que possible. L’inconvénient est qu’on ne sait plus sur quel nœud une ligne particulière est située, ce qui oblige à scruter tous les nœuds en parallèle pour la plupart des requêtes.
- L’affectation par hachage est une combinaison des deux méthodes précédentes. Comme dans l’affectation round-robin, elle évite les déséquilibres de charge en utilisant une fonction hash sur la clé afin d’obtenir une distribution pseudo-aléatoire des lignes sur les nœuds et par conséquent des partitions relativement homogènes en termes de cardinalité. Comme dans l’affectation par intervalle, le hachage assure également que les lignes qui ont une valeur de clé identique soient dans la même partition et donc affectées au même nœud (colocalisation des données de même valeur de clé). Ainsi, les jointures sont plus simples à réaliser et il n’y aura pas besoin de déplacer les données dans le cluster.
Nous allons illustrer concrètement tous ces principes que nous venons de voir avec GreenPlum, un SGBDR MPP développé par Pivotal. Considérons la base de données parallèle contenant la table products suivante :
| product_id | product_name | price |
| 10001 | Tablette Amazon Kindle | 56 |
| 10002 | Iphone Apple 5S Nano | 400 |
| 10003 | Book on digital markteing | 10 |
| 10004 | Smooking soirée VIP | 250 |
| 10005 | PC Dell Xperion | 300 |
| 10006 | Nokia PC | 250 |
| 10007 | Calculatrice X008 | 70 |
| 10008 | James Bond le film | 25 |
| 10009 | Livre leadership | 19 |
| 10010 | gillette max 3 Fusion | 14 |
| 10011 | chaussures Homme | 55 |
| 10012 | Costume Class | 195 |
Supposons que la base de données est parallélisée sur un cluster de trois nœuds. La figure suivante illustre l’architecture d’un SGBDR MPP classique.

La distribution des données se fait par partitionnement horizontal des données des tables de la base de données parallèle. Dans GreenPlum, cela s’accomplit lors de la création de la table avec le SQL par l’instruction DISTRIBUTED BY. GreenPlum propose deux modes d’affectation des partitions aux nœuds de données : l’affection round-robin et l’affectation par hachage. Dans cet exemple, nous allons utiliser l’affection par hachage. Nous allons également utiliser comme clé de partitionnement product_id.
La requête de création de la table products est la suivante :
Sélectionnez
1.
2.
3.
4.
5.
CREATE TABLE products ( product_id INTEGER, product_name varchar(200), price DOUBLE ) DISTRIBUTED BY (product_id) ; Une fois que la table a été créée, nous pouvons maintenant insérer les 13 lignes de la table et voir l’effet du hachage sur l’affectation des lignes aux nœuds de données.
Sélectionnez
1.
2.
3.
4.
INSERT INTO products VALUES (1001, 'Tablette Amazon Kindle', 56); INSERT INTO products VALUES (1002, 'Iphone Apple 5S Nano', 400); …… …… …… …… …… … …… INSERT INTO products VALUES (1012, 'Costume Class', 195); La figure suivante illustre le partitionnement et la distribution des données dans la base parallèle.
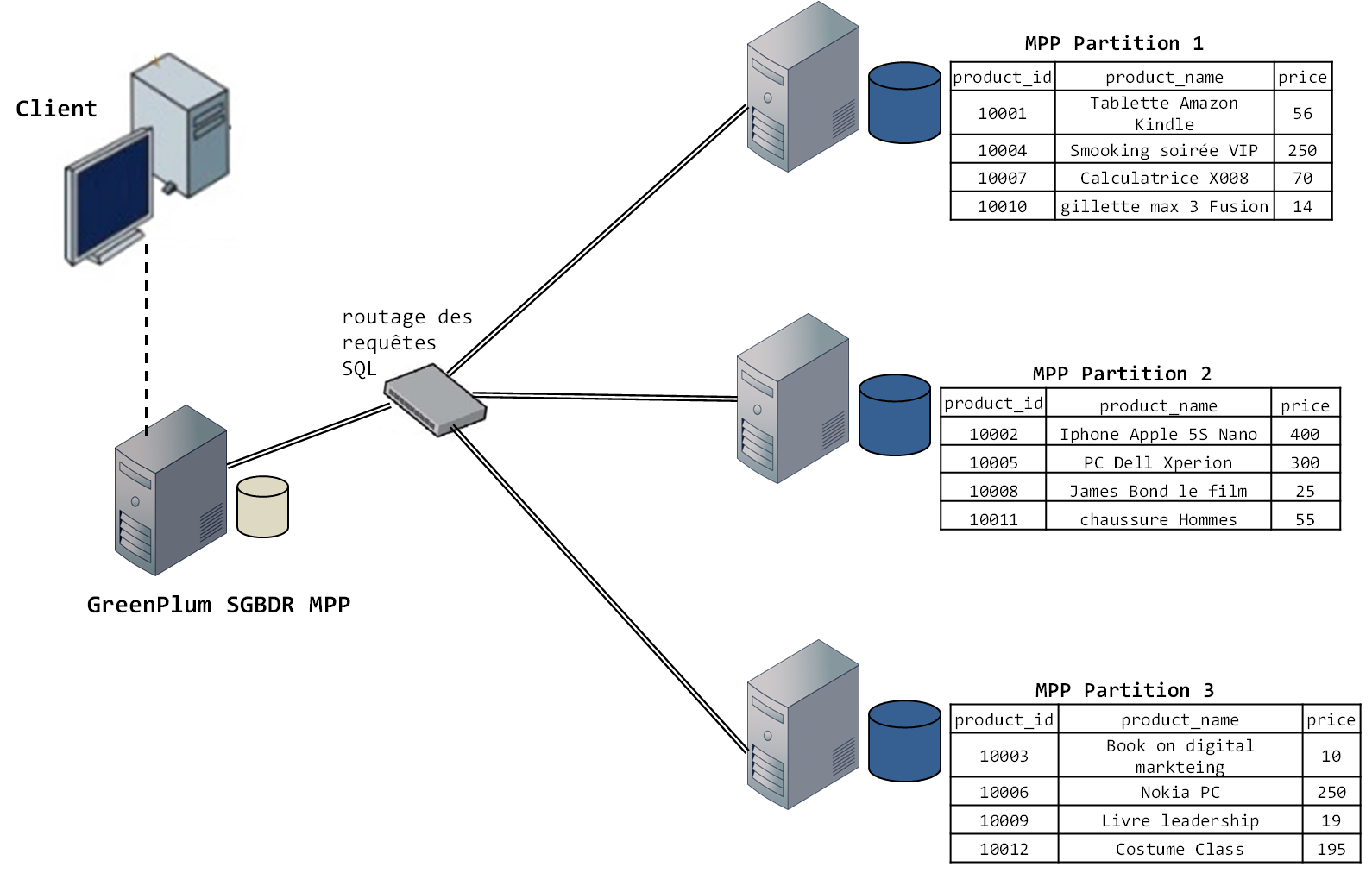
Remarquez que les tables partitionnées sont bien réparties (elles ont toute la même taille) et que les valeurs sont distribuées de façon aléatoire. Ce sont là les caractéristiques de l’affectation par hachage. Si l’affectation s’était faite par exemple par intervalle, les lignes auraient été partitionnées par valeur consécutive, et n’auraient pas nécessairement été aussi bien réparties. Nous allons maintenant passer au deuxième aspect des bases parallèles : l’exécution des requêtes SQL.
II-B. L’exécution des requêtes SQL dans les bases massivement parallèles
Les SGBDR s’interrogent avec un langage bien connu, qui sert aussi bien de langage d’interrogation que de langage de définition de données : le SQL (Structured Query Language). Tout comme le HiveQL, le SQL permet à l’utilisateur de décrire les opérations à effectuer sur la base de données à l’aide d’un ensemble de clauses. Le SQL est le standard en matière d’interrogation des bases de données relationnelles et par sa syntaxe simple, est devenu depuis, le langage favori des utilisateurs. En réalité, le SQL fonctionne également comme une abstraction, elle permet à l’utilisateur de décrire le QUOI sans décrire le COMMENT, c’est d’ailleurs le but de tout langage de requête par nature. Les requêtes SQL ne sont pas directement exécutées, elles passent toutes par trois phases :
- premièrement, leur syntaxe est vérifiée par le système. Si l’utilisateur a mal saisi le code ou s’est trompé sur l’écriture d’une clause, alors le système génère une erreur et le programme s’arrête ;
- deuxièmement, lorsque la syntaxe de la requête est validée, la requête SQL est transformée en plan d’exécution, après algébrisation et optimisation, ce qui conduit à livrer un arbre de décision hiérarchique similaire à un graphe acyclique direct qui indique au moteur du SGBDR l’ordre dans lequel les clauses de la requête doivent être exécutées ;
- dernièrement, le plan d’exécution est compilé en instructions machine et ce sont ces instructions qui sont exécutées par le processeur de la machine sur laquelle le SGBDR est installé. La figure suivante illustre le processus classique d’exécution d’une requête SQL.

Attention, dans un contexte distribué en général appliqué à un SGBDR parallèle en particulier, le processus général est le même, mais le schéma d’exécution diffère. En effet, les requêtes SQL sont décomposées en processus parallèles, et exécutées de façon concurrente sur tous les nœuds contenant une partition de la base de données. Ce sont donc les mêmes instructions (la même requête SQL) qui sont exécutées simultanément sur chacun des nœuds du cluster. La machine centrale et les nœuds de calcul sont impliqués dans l’exécution de la requête. La machine centrale génère le plan d’exécution de la requête SQL et la répartit aux nœuds de calcul contenant une partition de la base de données, tandis que les nœuds de calcul la compilent et l’exécutent. De façon générale, la requête suit le schéma décrit par la figure suivante :

En fonction du type de requête, le plan d’exécution n’est pas le même. Nous allons illustrer cette figure avec trois exemples. Reprenons le cas précédent et considérons que nous voulons réaliser une restriction (opération consistant à retrouver certaines lignes d’une table) en recherchant les lignes pour lesquelles l’identifiant du produit vaut 10005. La requête SQL qui permet de faire cela est la suivante :
SELECT * FROM products WHERE poduct_id = 10005;
Regardons comment cette requête s’exécute dans la base de données parallèle et l’impact du partitionnement de la table sur la performance de la requête. Lorsque cette requête est lancée, elle est transformée en plan d’exécution par le nœud central du cluster. Étant donné que cette requête filtre sur une valeur de la colonne qui sert de clé de partitionnement, le plan d’exécution va être envoyé uniquement sur le nœud contenant la valeur 1005 (le nœud 2 dans notre exemple) et celui-ci va la compiler, l’exécuter sur sa partition et renvoyer le résultat à la machine centrale. La performance est alors meilleure que si la base était partagée en mémoire (comme dans les architectures centralisées ou les architectures Shared-Memory). La machine centrale est capable de déclencher le nombre exact de processus SQL qu’il faut, parce que le nœud de référence d’Hadoop, stocke les métadonnées concernant la distribution de la base de données. En d’autres termes, la machine centrale connait où sont localisées toutes les partitions des tables de la base de données et leur valeur.
Supposons maintenant que nous voulons sélectionner les produits : 10001, 10002, 10003, 10004, 10005 et 10006. La requête correspondante est la suivante :
SELECT * FROM products WHERE poduct_id between 10001 AND 10006;
Lorsque cette requête est exécutée, la machine centrale la transforme en plan d’exécution, ensuite elle identifie dans ses métadonnées la localisation de chacune des valeurs du filtre et déclenche N processus d’exécution égal aux N partitions/nœuds où sont stockées ces données (dans notre exemple, les trois nœuds de calcul). Les trois processus vont s’exécuter en parallèle sur les trois nœuds contenant les partitions et les résultats seront transférés vers le master, qui va les concaténer pour obtenir la table finale de résultat.
Vous voyez une fois de plus que l’exécution parallèle augmente drastiquement la performance des requêtes et permet de tirer pleinement profit des machines du cluster.
Pour le troisième cas, supposons que nous voulons effectuer une jointure entre deux tables. La figure 6 ci-après illustre une base de données parallèle composée de deux tables : la table products et la table orders. Chaque nœud aura une réplique de la structure de la base de données et une partition des deux tables comme illustré par la figure. Si les deux tables à joindre sont partitionnées selon la même clé, alors la jointure va se faire localement sur chaque nœud, ensuite les résultats de chacun seront transférés vers la machine centrale qui va les agréger. Si les deux tables ne sont pas distribuées selon la même clé, le SGBD Parallèle va utiliser les statistiques de la table pour copier les données de la plus petite table pour la placer dans le nœud de la plus grande pour effectuer la jointure. L’avantage avec les SGBDR MPP est que si les jointures deviennent coûteuses, alors vous pouvez simplement augmenter la performance du cluster en y augmentant le nombre de nœuds de calcul.
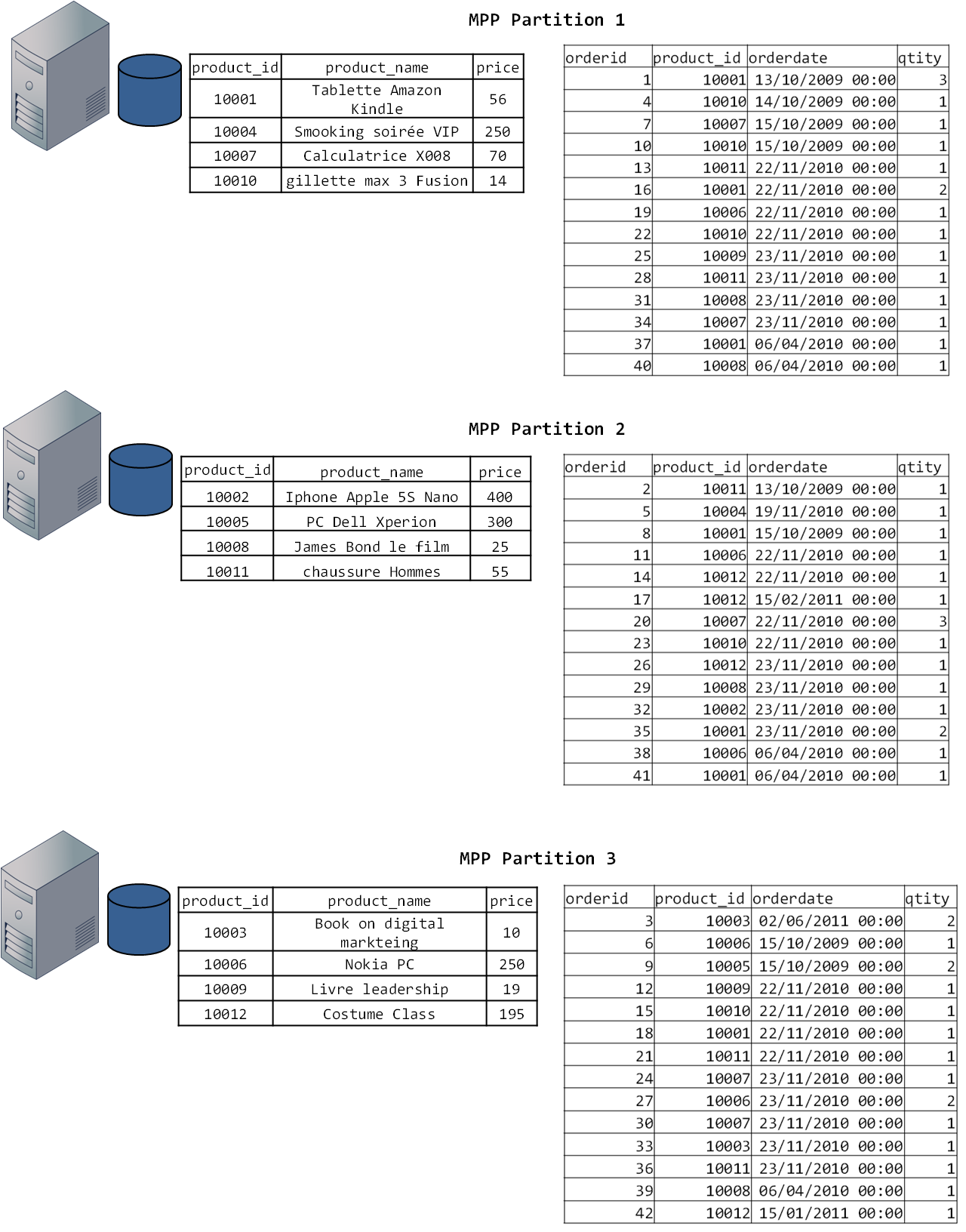
Voilà, maintenant que vous connaissez en détail le fonctionnement des SGDBR massivement parallèles, vous êtes prêts pour comprendre le fonctionnement des moteurs SQL MPP sur Hadoop.
III. Fonctionnement des moteurs natifs SQL sur hadoop
Originellement, le SQL est le langage des moteurs de bases de données relationnelles. Les bases de données relationnelles elles-mêmes tirent leur origine de la théorie de l’algèbre relationnelle et ont été mises au point par Edgar Frank CODD. Lorsqu’ Edgard Franck CODD créait le SQL, c’était pour fournir aux utilisateurs un langage déclaratif permettant de définir des opérations relationnelles (les tables et les vues), de les interroger (projections, groupes, filtres, jointures) et d’être interprété par des moteurs relationnels à l’exemple de SQL Server, DB2, Oracle. Il est très important que vous compreniez que le SQL est un langage de définition et d’interrogation des tables (données structurées en lignes colonnes) et que les requêtes SQL ne peuvent s’exécuter que par des moteurs de bases de données relationnelles. Les expressions « Moteur SQL sur Hadoop » ou « Moteurs natifs SQL sur Hadoop » ne font pas référence à des moteurs relationnels distribués sur Hadoop, mais à des systèmes qui sont capables de fournir une couche de programmation SQL telle que spécifiée par la norme ANSI (SQL ANSI 92, SQL ANSI 2003, etc.) pour la spécification des travaux de traitement de données et fournir un moteur d’exécution de ces travaux directement sur les données stockées dans un cluster Hadoop. Hive a été le tout premier du genre. À la différence de Hive, ces systèmes ne transforment pas les requêtes SQL en jobs MapReduce, ni en un quelconque autre modèle de calcul distribué. Ils ne présentent pas juste une interface SQL. Ils exécutent directement le plan d’exécution des requêtes SQL de façon parallèle dans le cluster Hadoop. Comme nous l’avons vu plus haut, vous savez que le SQL ne s’exécute pas tel qu’il a été écrit par l’utilisateur, il est transformé en plan d’exécution et c’est ce plan qui est compilé et exécuté. Les moteurs SQL natifs Hadoop exécutent directement le plan d’exécution des requêtes SQL sur le cluster Hadoop. C’est pourquoi on dit d’eux qu’ils sont « natifs SQL ». Le but qui est à l’origine de ces systèmes est de connecter les applications SQL existantes dans les systèmes décisionnels des entreprises à la puissance de calcul d’Hadoop, et ainsi de faciliter l’adoption d’Hadoop par les utilisateurs métier et les entreprises.
III-A. Différences entre les SGBDR MPP et les moteurs SQL natifs sur Hadoop
Nous allons vous présenter les principes et les choix qui sont à la base d’un moteur SQL sur Hadoop et prendre l’exemple d’un d’entre eux : Impala. Actuellement, le marché regorge de plusieurs moteurs SQL sur Hadoop : Cloudera Impala, HadoopDB, Google Dremel, Apache Phoenix, Apache HAWQ, Apache Drill, Facebook Presto, VectorH, Vortex ou encore Spark SQL. Pour pouvoir exécuter de façon massivement parallèle du SQL sur un cluster Hadoop, les moteurs SQL sur Hadoop se sont inspirés du fonctionnement des SGBDR MPP et des principes des bases de données parallèles. Par exemple, le code source d’HadoopDB est constitué en majorité du code source de PostgreSQL, celui de HAWQ en majorité de GreenPlum, et Vortex celui de Vectorwise. Par contre, la ressemblance entre les deux types de systèmes s’arrête là. On note trois différences majeures entre les deux :
- là où les SGBDR MPP doivent implémenter des mécanismes propriétaires de tolérance aux pannes, de réplication et de haute disponibilité, les moteurs SQL sur Hadoop s’appuient directement sur le HDFS pour fournir la haute disponibilité et la tolérance aux pannes nécessaires au traitement distribué ;
- les SGDR MPP s’exécutent uniquement sur des tables relationnelles, tandis que les moteurs SQL sur Hadoop s’exécutent sur les données stockées dans le HDFS. Ces données peuvent être structurées (tables relationnelles, fichiers plats CSV) ou pas (fichiers JSON, XML, etc.). Là où les SGBDR MPP ont un contrôle sur les tables qu’ils manipulent, les moteurs SQL sur Hadoop eux n’en ont quasiment pas, des fichiers peuvent s’ajouter, être modifiés ou être supprimés du HDFS sans notification au moteur SQL sur Hadoop, compliquant ainsi l’optimisation des requêtes ;
- les SGBDR MPP sont plus coûteux financièrement qu’Hadoop. Coûteux financièrement en termes de logiciel, de matériel, d’administration, et même en termes de compétences (les développeurs et administrateurs de SGBDR MPP sont très rares). Hadoop par contre est open source et est en train de devenir le standard du traitement massivement parallèle. Acquérir des compétences sur Hadoop se vulgarise de plus en plus.
Deux aspects gouvernent l’implémentation d’un moteur SQL MPP sur Hadoop. Les différences entre les solutions SQL sur Hadoop proviennent essentiellement de l’arbitrage entre les options offertes par ces deux aspects : le mode de stockage et la structure des données.
– Le mode de stockage
Le premier aspect le plus important des moteurs SQL sur Hadoop est leur mode de stockage. Paralléliser l’exécution des requêtes SQL sur les nœuds d’un cluster suppose que les traitements se fassent in situ, c’est-à-dire en local sur chaque nœud. Dans un SGBDR parallèle, les traitements sont faits in situ par la réplication de la structure de la base de données et de ses tables aux nœuds de calcul du cluster. Dans un cluster Hadoop c’est le HDFS qui assure ce rôle de réplication. Le HDFS est le composant qui assure le traitement in situ dans un cluster Hadoop. Pour faire le traitement in situ, les éditeurs de moteurs SQL sur Hadoop ont le choix entre trois options : soit ils s’appuient directement sur le HDFS pour le stockage, soit ils stockent les données dans les nœuds de calcul, sur un système de stockage différent du HDFS (par exemple un autre SGBD), soit alors ils transforment dynamiquement les données du HDFS en données propriétaires (par exemple en table relationnelle, en table HBase, etc.). Ce choix aura un impact sur la façon dont le moteur va exécuter les requêtes (exécution par le moteur, exécution par le SGBD, ou exécution partagée entre le SGBD et le moteur) et sur les SGBD auxquels le moteur pourra se connecter.
– La structure des données
Le deuxième aspect qui gouverne le développement d’un moteur SQL sur Hadoop est la structure des données. Dans les SGBDR parallèles, toutes les données sont stockées sous forme de tables. Dans un cluster Hadoop par contre, les données sont stockées dans le HDFS, sous des formes complexes comme le JSON, XML, RDF, HTML ou sous forme de fichiers plats. Les éditeurs ici ont le choix entre trois options : soit ils supportent les formats natifs HDFS et n’imposent pas de format propriétaire, soit ils imposent un format spécifique (généralement propriétaire), soit alors ils transforment les données de leur structure de base en un format spécifique. Rares sont les moteurs SQL sur Hadoop qui, comme Apache Drill, sont capables d’exécuter du SQL sur des formats semi-structurés (XML, JSON).
Maintenant nous allons donner le fonctionnement général d’un moteur SQL sur Hadoop. De façon générale, tout comme les SGBDR MPP, les requêtes sont réceptionnées par une machine centrale (le NameNode du cluster dans certain cas, ou une machine différente qui fait office de serveur racine dans d’autres cas), ensuite celle-ci les transforme en plan d’exécution, les distribuent entre les nœuds de calcul où un processus du moteur y est continuellement en cours d’exécution. Deux cas peuvent apparaître : si le moteur s’appuie sur le HDFS alors ce processus va compiler la requête et l’exécuter directement sur le HDFS, si le moteur s’appuie sur un système de stockage différent du HDFS ou transfère les données du HDFS en format spécifique, alors la charge de calcul sera partagée entre le processus du moteur et le SGBD du système de stockage. Dans d’autres moteurs, les requêtes sont directement réceptionnées par les nœuds de calcul, transformées en plan d’exécution, compilées et traitées par ceux-ci. Nous allons voir l’implémentation concrète de tous ces principes à l’aide d’un exemple concret : Impala.
III-B. Impala : le moteur SQL sur Hadoop de Cloudera
Cloudera est un éditeur de solutions logicielles, le fournisseur de la distribution commerciale d’Hadoop CDH. Cloudera est connu pour l’une de ses innovations majeures : Impala. Impala est un moteur SQL MPP sur Hadoop open source (Impala a rejoint la fondation Apache depuis 2014, mais son développement reste toujours supervisé par Cloudera). Le but d’Impala est double : d’une part combiner le SQL et la performance multiutilisateur des moteurs OLAP(1) à la scalabilité et la flexibilité d’Hadoop, et d’autre part y ajouter les extensions de sécurité et d’administration de Cloudera CDH. Impala permet aux utilisateurs d’écrire et d’exécuter des requêtes SQL sur des données stockées dans le HDFS ou dans HBase, exactement de la même façon que vous écririez et exécuteriez vos requêtes SQL sur des bases de données Oracle, ou SQL Server. Parce qu’il peut utiliser les métadonnées Hive, Impala est capable de lire des tables Hive et d’interpréter des scripts rédigés en HiveQL.
Comme nous l’avons dit plus haut dans l’étude des moteurs SQL MPP traditionnels, l’un des plus grands challenges que pose le développement d’un moteur SQL sur Hadoop est la coordination et la synchronisation des nœuds du cluster autour des métadonnées partagées. En effet, il faut que tous les nœuds soient capables de recevoir et d’exécuter les requêtes en local, ce qui requiert qu’ils aient tous accès à la version la plus à jour des métadonnées. La majorité des moteurs résolvent ce problème en s’appuyant sur une architecture maître/esclave où une machine centrale héberge les métadonnées du moteur et l’utilise pour distribuer les requêtes aux nœuds de calcul. Impala quant à lui, résout ce challenge en adoptant une architecture distribuée Peer-to-Peer et asymétrique, organisée autour de trois composants centraux :
– Les processus Impala, encore appelé Impalad (pour Impala Deamon), ce sont les processus qui s’exécutent en permanence sur chaque nœud de données du cluster (un processus impalad par nœud). Ils reçoivent les requêtes SQL transmises par le biais de l’interface de commande Impala (CLI), Hue, le JDBC ou l’ODBC, lisent et écrivent les fichiers de données nécessaires, parallélisent et distribuent l’exécution des requêtes dans le cluster et transmettent les résultats intermédiaires des requêtes au Name Node. Les processus impala communiquent directement les uns avec les autres pour exécuter les requêtes, ce qui fait que vous pouvez soumettre vos requêtes à n’importe quel nœud de données du cluster. Chaque processus Impala est en communication constante avec le statestore pour être au courant des nœuds qui sont en bon état et qui peuvent accepter de nouvelles requêtes.
- Le Statestore vérifie l’état de fonctionnement de tous les processus Impala du cluster et leur envoie continuellement les informations de cette vérification. Le statestore est physiquement représenté par un processus appelé statestored, exécuté sur une seule machine dans le cluster. En cas de panne d’un nœud, le statestore informe tous les autres processus impala d’éviter d’envoyer les futures requêtes vers le nœud en panne ;
- Le service de catalogue relaie les mises à jour des métadonnées des instructions SQL à tous les nœuds de données du cluster. Il est physiquement représenté par un processus appelé catalogd (catalog deamon), exécuté sur une seule machine dans le cluster. Il est recommandé de faire tourner les processus catalogd et statestored sur la même machine. Le service de catalogue évite à l’utilisateur de devoir rafraîchir manuellement les métadonnées à chaque mise à jour dans les requêtes SQL.
La figure suivante illustre l’architecture et le fonctionnement d’Impala.
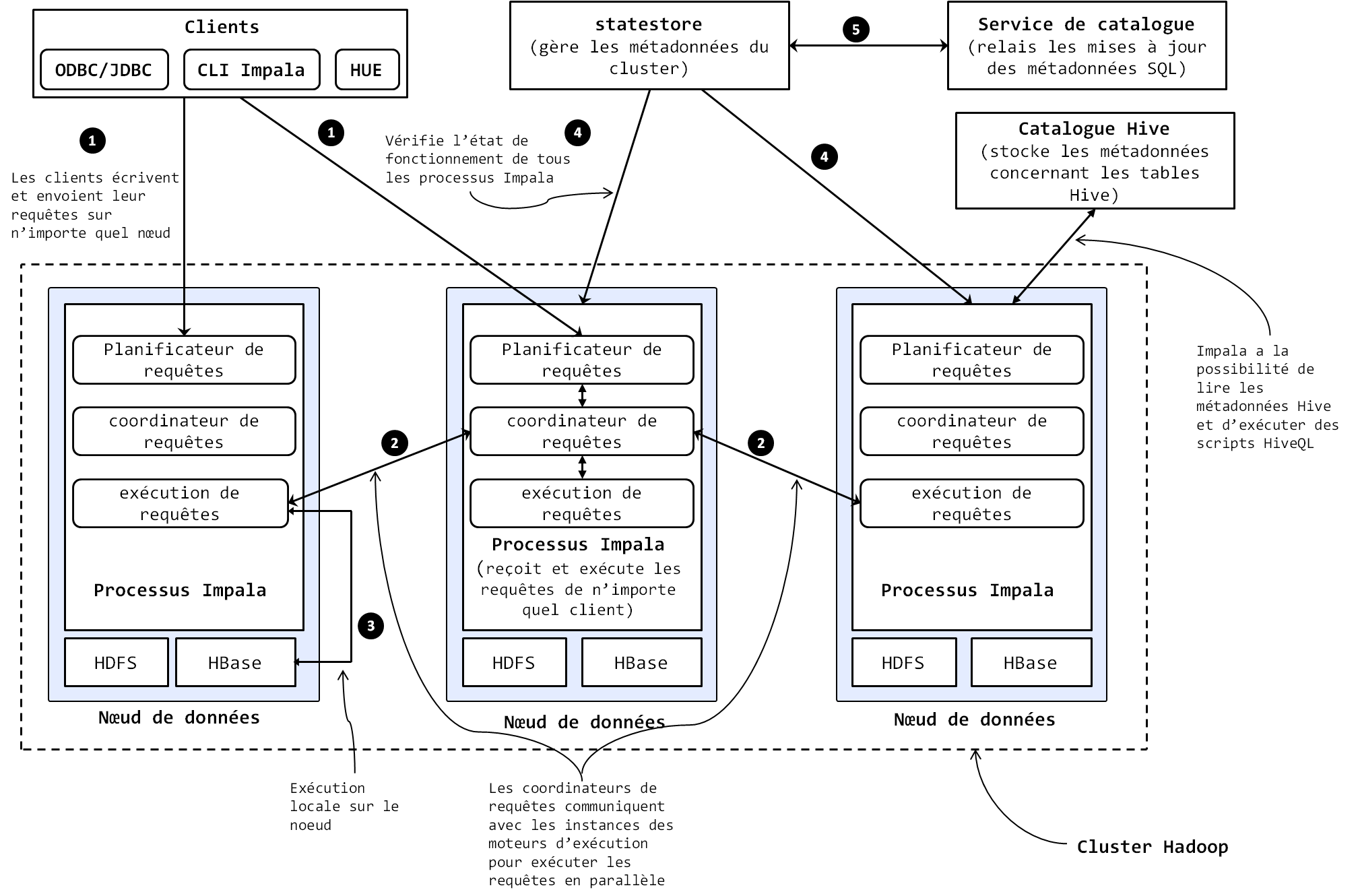
|
Grâce à cette architecture, Impala affiche des performances plus élevées que la majorité des moteurs SQL sur Hadoop (Spark SQL, Presto de Facebook). Pour plus de détails sur Impala, veuillez vous rendre sur le site officiel de Cloudera ou sur le site Hadoop des projets en état d’incubation. Pour le reste, la spécification SQL d’Impala reste presque à tout point identique à la spécification du SQL que vous connaissez déjà.
IV. Conclusion
Nous sommes arrivés à la conclusion de la série de tutoriels Le SQL dans Hadoop. Dans ces deux tutoriels, nous vous avons montré que l’adoption à large échelle et le succès d’Hadoop ne dépend pas des développeurs Java, mais contre toute attente des utilisateurs métier. Ceux-ci ne s’y connaissent généralement pas en programmation et ont l’habitude de développer leurs applications d’exploitation de données en SQL. Facebook a été le premier à réagir à ce constat et a proposé Hive. Dans le premier tutoriel, nous avons vu que Hive est une infrastructure similaire au DataWarehouse qui fournit aux utilisateurs un langage d’interrogation de données similaire au SQL : le HiveQL. Le premier problème avec HiveQL vient directement de sa nature : parce qu’il est un langage descriptif, la complexité des problèmes qu’on peut y exprimer est faible. Pour résoudre ce problème, Yahoo! a conçu le Pig Latin, un langage de flux de données suffisamment simple à utiliser par les analystes métier. En arrière-plan, ces langages transforment les requêtes des utilisateurs en job MapReduce. Avec l’évolution des besoins du numérique, la latence du MapReduce s’est trouvée inacceptable pour les problématiques interactives, il a donc fallu penser à de nouvelles approches, et c’est ainsi que les moteurs SQL sur Hadoop sont nés. Ceux-ci s’appuient sur les principes de fonctionnement des bases de données massivement parallèles et des SGBDR MPP qui sont utilisés pour gérer de grosses volumétries de bases de données relationnelles et des DataWarehouse à l’échelle du téraoctet. À la différence de Hive ou Pig, les moteurs SQL sur Hadoop exécutent nativement le SQL sur un cluster Hadoop sans le transformer en job MapReduce. D’ailleurs, en interne, Facebook a remplacé HiveQL par l’usage de Presto, son moteur SQL MPP sur Hadoop. Tout au long de ce tutoriel, nous vous avons conduit à comprendre les principes de fonctionnement des moteurs SQL MPP, de la façon dont le SQL est nativement exécuté sur Hadoop. Nous avons pris l’exemple d’Impala, le moteur SQL MPP sur Hadoop développé à l’origine par Cloudera. Comme cette série de tutoriels a été écrite pour ceux qui débutent sur Hadoop, ce tutoriel devrait vous donner plus d’assurance quant à votre capacité à exploiter Hadoop. Le SQL étant une compétence commode, vous devrez normalement à ce stade être opérationnel sur l’exploitation d’un cluster Hadoop, même si vous n’avez pas une grande maîtrise de la programmation distribuée en Java, C++, ou Python.
Si vous souhaitez allez plus loin dans le développement de vos compétences Big Data, chose que nous vous conseillons, n’hésitez pas à vous procurer l’ouvrage « Hadoop – Devenez opérationnel dans le monde du Big Data ». Vous y découvrirez plus en profondeur le SQL sur Hadoop, les architectures client-serveur, Shared-Nothing, Shared-Memory, Shared-Disk, et leur impact sur les traitements en Big Data, les spécificités du HDFS, l’impact des traitements in situ ou ex situ, les distributions Hadoop, entre autres. Pour vous assurer que vous avez bien validé les acquis de ces deux tutoriels, nous vous recommandons de passer en revue le miniguide d’étude suivant.
Miniguide de validation des acquis de compétences
Si vous le voulez, vous pouvez échanger vos réponses avec nous. Pour ce faire il vous suffit de nous adresser vos réponses à l’adresse mail suivante : contact.
Question : on peut utiliser Hadoop sans passer par un écosystème d’outils.
- Vrai
- Faux
Question : Hive est un langage SQL d’écriture des requêtes sous Hadoop.
- Vrai
- Faux
Question : Hive peut exécuter du code Python.
- Vrai
- Faux
Question : cochez la bonne réponse. Dans une base de données parallèle, la compilation des requêtes SQL se fait dans :
- la machine centrale du cluster ;
- les nœuds de calcul du cluster ;
- les deux.
Question : cochez la bonne réponse. Dans une base de données parallèle, la transformation des requêtes SQL en plan d’exécution se fait dans :
- la machine centrale du cluster ;
- les nœuds de calcul du cluster ;
- les deux.
Question : un moteur SQL sur Hadoop est un moteur de base de données relationnelle.
- Vrai
- Faux
Question : cochez la bonne réponse. Impala fonctionne sur une architecture
- asymétrique Peer-to-Peer ;
- symétrique maître/esclave ;
- les deux.
Question : soit le fichier de données suivant, stocké sur le HDFS dans le répertoire ‘projets/livre_hadoop/hive/orders.txt’. Nous souhaitons utiliser Hive pour effectuer des études statistiques sur ce fichier de données. Vous êtes l’analyste en charge de l’analyse. Utilisez le HiveQL pour répondre aux questions suivantes :
| orderid | customerid | orderdate | qtity |
| 3 | 10007 | 02/06/2011 00:00 | 2 |
| 6 | 10007 | 15/10/2009 00:00 | 1 |
| 9 | 10012 | 15/10/2009 00:00 | 2 |
| 12 | 10005 | 22/11/2010 00:00 | 1 |
| 15 | 10005 | 22/11/2010 00:00 | 1 |
| 18 | 10009 | 22/11/2010 00:00 | 1 |
| 21 | 10011 | 22/11/2010 00:00 | 1 |
| 24 | 10010 | 23/11/2010 00:00 | 1 |
| 27 | 10003 | 23/11/2010 00:00 | 2 |
| 30 | 10006 | 23/11/2010 00:00 | 1 |
| 33 | 10002 | 23/11/2010 00:00 | 1 |
| 36 | 10012 | 23/11/2010 00:00 | 1 |
| 39 | 10004 | 06/04/2010 00:00 | 1 |
| 42 | 10006 | 15/01/2011 00:00 | 1 |
- Écrivez le script HiveQL de création de la table orders ;
- Écrivez le script HiveQL d’insertion des lignes de ce fichier dans la table orders que vous
avez précédemment créée ; - Écrivez le script HiveQL de la somme des quantités par client.
Question : soit le fichier de données suivant, stocké sur le HDFS dans le répertoire ‘projets/livre_hadoop/pig/orders.txt’. Nous souhaitons utiliser Pig pour effectuer des études statistiques sur ce fichier de données. Vous êtes l’analyste en charge de l’analyse. Utilisez le Pig Latin pour répondre aux questions suivantes :
| orderid | customerid | orderdate | qtity |
| 3 | 10007 | 02/06/2011 00:00 | 2 |
| 6 | 10007 | 15/10/2009 00:00 | 1 |
| 9 | 10012 | 15/10/2009 00:00 | 2 |
| 12 | 10005 | 22/11/2010 00:00 | 1 |
| 15 | 10005 | 22/11/2010 00:00 | 1 |
| 18 | 10009 | 22/11/2010 00:00 | 1 |
| 21 | 10011 | 22/11/2010 00:00 | 1 |
| 24 | 10010 | 23/11/2010 00:00 | 1 |
| 27 | 10003 | 23/11/2010 00:00 | 2 |
| 30 | 10006 | 23/11/2010 00:00 | 1 |
| 33 | 10002 | 23/11/2010 00:00 | 1 |
| 36 | 10012 | 23/11/2010 00:00 | 1 |
| 39 | 10004 | 06/04/2010 00:00 | 1 |
| 42 | 10006 | 15/01/2011 00:00 | 1 |
- Écrivez le script Pig de création de la table orders ;
- Écrivez le script Pig d’insertion des lignes de ce fichier dans la table orders que vous avez précédemment créée ;
- Écrivez le script Pig de la somme des quantités par client.
Question : soit la table orders suivante qui fait partie de la base de données parallèle orders_system installée sur GreenPlum. Cette base de données parallèle est répliquée sur un cluster de trois nœuds de calcul. Répondez aux questions suivantes :
| orderid | customerid | orderdate | qtity |
| 1 | 10006 | 13/10/09 00:00 | 3 |
| 2 | 10010 | 13/10/09 00:00 | 1 |
| 3 | 10001 | 02/06/11 00:00 | 2 |
| 4 | 10003 | 14/10/09 00:00 | 1 |
| 5 | 10004 | 19/11/10 00:00 | 1 |
| 6 | 10002 | 15/10/09 00:00 | 1 |
| 7 | 10001 | 15/10/09 00:00 | 1 |
| 8 | 10006 | 15/10/09 00:00 | 1 |
| 9 | 10004 | 15/10/09 00:00 | 2 |
| 10 | 10004 | 15/10/09 00:00 | 1 |
| 11 | 10007 | 22/11/10 00:00 | 1 |
| 12 | 10011 | 22/11/10 00:00 | 1 |
| 13 | 10007 | 22/11/10 00:00 | 1 |
| 14 | 10012 | 22/11/10 00:00 | 1 |
| 15 | 10003 | 22/11/10 00:00 | 1 |
| 16 | 10012 | 22/11/10 00:00 | 2 |
| 17 | 10005 | 15/02/11 00:00 | 1 |
| 18 | 10009 | 22/11/10 00:00 | 1 |
| 19 | 10012 | 22/11/10 00:00 | 1 |
| 20 | 10011 | 22/11/10 00:00 | 3 |
| 21 | 10003 | 22/11/10 00:00 | 1 |
- Écrivez la requête SQL de création de la table orders et spécifiez-y qu’elle est distribuée. La clé de partitionnement c’est le champ orderid ;
- Après avoir exécuté la requête, GreenPlum présente les partitions ci-après. À quel mode d’affection de partition correspond ce résultat ? Justifiez votre réponse
……………………………………………………………………………………………………………………………….
……………………………………………………………………………………………………………………………..
……………………………………………………………………………………………………………………………
……………………………………………………………………………………………………………………………….
Partition 1
| orderid | product_id | orderdate | qtity |
| 1 | 10001 | 13/10/09 00:00 | 3 |
| 4 | 10010 | 14/10/09 00:00 | 1 |
| 7 | 10007 | 15/10/09 00:00 | 1 |
| 10 | 10010 | 15/10/09 00:00 | 1 |
| 13 | 10011 | 22/11/10 00:00 | 1 |
| 16 | 10001 | 22/11/10 00:00 | 2 |
| 19 | 10006 | 22/11/10 00:00 | 1 |
Partition 2
| orderid | product_id | orderdate | qtity |
| 2 | 10011 | 13/10/09 00:00 | 1 |
| 5 | 10004 | 19/11/10 00:00 | 1 |
| 8 | 10001 | 15/10/09 00:00 | 1 |
| 11 | 10006 | 22/11/10 00:00 | 1 |
| 14 | 10012 | 22/11/10 00:00 | 1 |
| 17 | 10012 | 15/02/11 00:00 | 1 |
| 20 | 10007 | 22/11/10 00:00 | 3 |
Partition 3
| orderid | product_id | orderdate | qtity |
| 3 | 10003 | 02/06/11 00:00 | 2 |
| 6 | 10006 | 15/10/09 00:00 | 1 |
| 9 | 10005 | 15/10/09 00:00 | 2 |
| 12 | 10009 | 22/11/10 00:00 | 1 |
| 15 | 10010 | 22/11/10 00:00 | 1 |
| 18 | 10001 | 22/11/10 00:00 | 1 |
| 21 | 10011 | 22/11/10 00:00 | 1 |
- Nous écrivons et exécutons la requête suivante :
SELECT*FROMordersWHEREpoduct_id=10003; Expliquez le processus d’exécution de cette requête.
…………………………………………………………………………………………………………………………………………………………………………………… …………………………………………………………………………………………………………………………………………………………………………………… …………………………………………………………………………………………………………………………………………………………………………………… …………………………………………………………………………………………………………………………………………………………………………………… - Nous écrivons et exécutons la requête suivante :
SELECT*FROMordersWHEREorderid=1; Expliquez le processus d’exécution de cette requête.
Ressources complémentaires
Pour aller plus loin dans l’apprentissage du SQL sur Hadoop, nous vous recommandons les ressources suivantes :
- Vous pouvez revenir sur les fondements du SQL sur Hadoop avec le tutoriel suivant : le SQL dans Hadoop – Hive & Pig
- Pour la documentation complète sur Impala, rendez-vous sur le site d’Apache : https://impala.apache.org/
- en réalité, Impala n’est pas le seul moteur SQL natif sur Hadoop. Il existe un autre également très performant, Apache HawQ : http://hawq.apache.org/
Lectures recommandées
Nous vous recommandons les ouvrages suivants pour parfaire votre apprentissage du SQL sur Hadoop (Hive, Pig, Pig Latin, Impala, Phoenix, etc…). Ces ouvrages vous feront gagner énormément de temps :

Hadoop Devenez opérationnel dans le monde du Big Data, cet ouvrage est le premier ouvrage de notre projet DTN. Il vous aidera à comprendre plus en profondeur le fonctionnement des moteurs SQL sur Hadoop. De façon plus général, il vous aidera à développer les compétences technique de base dont vous avez besoin pour travailler efficacement dans le Big Data. Si vous vous lancez dans le Big Data, alors nous vous recommandons fortement de commencer par cet ouvrage.

Maîtrisez l’utilisation des technologies Hadoop, le deuxième ouvrage du projet DTN. Il fournit un ensemble de tutoriels pratiques pour monter en compétence non seulement sur les technologies du SQL sur Hadoop, mais également les moteurs natifs SQL sur Hadoop tels que Impala, Phoenix ou HawQ. De plus, si vous travaillez déjà sur un projet Big Data, cet ouvrage vous sera d’une grande assistance sur l’utilisation pratique de 18 technologies centrales de l’écosystème Hadoop

Hadoop, The Definitive Guide, 4ème édition, grand classique de l’apprentissage d’Hadoop, cet excellent ouvrage de Tom White des éditions Oreilly couvre en profondeur les technologies principales de l’écosystème Hadoop. Il faut noter que Tom White travaille chez Cloudera et est lui-même très impliqué dans le développement des technologies Hadoop
Vous travaillez sur un projet Big Data et vous souhaitez vous faire accompagner d’un point de vue technique, technologique ou stratégique ? Vous rencontrez des difficultés particulières avec une technologie de l’écosystème Hadoop ? Laissez vos questions en commentaires


