Lorsque l’on travaille dans le Big Data, il est important de se doter des meilleurs outils possible afin de mieux gérer les tâches qui nous sont confiées.
Dans cet article, nous allons vous présenter un outil, ou plus précisément l’IDE IntelliJ, essentiels pour une personne souhaitant œuvrer dans le Big Data, notamment pour les Data Engineer.
Vue d’ensemble de Intellij
IntelliJ est l’un des environnements de développement intégré (IDE) les plus puissants et les plus populaires pour les langages de la JVM. Il est développé et maintenu par JetBrains et disponible en édition community et ultimate. Cet IDE riche en fonctionnalités permet un développement rapide et aide à améliorer la qualité du code. Il fournit une palette d’outils pour développer des projets de Big data.
Qu’est-ce qu’un IDE et quels sont ses avantages ?
Pour mieux comprendre cet outil, il faut tout d’abord comprendre ce qu’est un IDE et quel est son utilité dans le développement informatique et éventuellement dans le Big Data.
IDE signifie « Integrated Development Environment » (environnement de développement intégré). Il s’agit d’une combinaison de plusieurs outils, qui rendent le processus de développement de logiciels plus facile, plus robuste et moins sujet aux erreurs. Par rapport à un simple éditeur de texte, il présente les avantages suivants
- Intégration avec des outils utiles tels que le compilateur, le débogueur, le système de contrôle de version, les outils de construction, divers cadres, les profileurs d’application, etc.
- Prise en charge de la navigation dans le code, de la complétion du code, du remaniement du code et des fonctions de génération de code, ce qui stimule le processus de développement.
- Prends en charge les tests unitaires, les tests d’intégration et la couverture du code via des plug-ins.
- Fournis un riche ensemble de plug-ins pour améliorer encore les fonctionnalités de l’IDE.
Caractéristiques d’IntelliJ qui facilitent le travail des data engineer
IntelliJ IDEA possède des fonctions de complétion de code Java très productives. Son algorithme prédictif peut supposer avec précision ce qu’un codeur tente de taper, et le complète pour lui, même s’il ne connaît pas le nom exact d’une classe particulière, d’un membre ou de toute autre ressource. Si vous souhaitez apprendre davantage la programmation Java, nous avons détaillé le sujet pour vous dans un article.
Une vision approfondie
IntelliJ IDEA comprend vraiment et a une vision profonde de votre code, ainsi que du contexte du codeur, ce qui le rend unique parmi les autres IDE Java.
Complétion de code intelligente – Il prend en charge la complétion de code basée sur le contexte. Il fournit une liste des symboles les plus pertinents applicables dans le contexte actuel.
Complétion de code en chaîne -Il s’agit d’une fonctionnalité avancée, conçue pour la compétition de code automatique. Elle liste les symboles applicables à travers les méthodes et les getters dans le contexte actuel.
Complétion des membres statiques – Elle vous permet d’utiliser des méthodes ou des constantes statiques et ajoute automatiquement les déclarations d’importation requises pour éviter les erreurs de compilation.
Détection des doublons – Il trouve les fragments de code en double et en informe l’utilisateur par une notification.
Inspections et corrections rapides – Chaque fois qu’IntelliJ détecte que vous êtes sur le point de faire une erreur, une petite ampoule de notification apparaît sur la même ligne. En cliquant dessus, la liste des suggestions s’affiche.
Ergonomie pour les data engineers
IntelliJ IDEA est conçu autour du principe que les data engineers doivent pouvoir écrire des codes avec le moins de distraction possible. C’est pourquoi, dans ce cas, l’éditeur est la seule chose visible à l’écran, avec des raccourcis dédiés pour toutes les autres fonctions non liées au codage. Pour mieux cerner le travail d’un Data Engineer, veuillez consulter l’article qui détaille les fonctions de ce métier.
Environnement centré sur l’éditeur – Des fenêtres contextuelles rapides permettent de vérifier des informations supplémentaires sans quitter le contexte actuel.
Raccourcis pour tout – IntelliJ IDEA dispose de raccourcis clavier pour presque tout, y compris la sélection rapide et le passage d’une fenêtre d’outils à l’autre, et bien d’autres choses encore.
Débogueur en ligne – Le débogueur en ligne vous permet de déboguer une application dans l’IDE lui-même. Il rend le processus de développement et de débogage transparent.
Outils intégrés pour les data engineers
Pour aider les développeurs à organiser leur flux de travail, IntelliJ IDEA leur offre un ensemble d’outils étonnants, qui comprend un décompilateur, un support Docker, un visualiseur de bytecode, un FTP et de nombreux autres outils.
Contrôle de version – IntelliJ prend en charge la plupart des systèmes de contrôle de version populaires comme Git, Subversion, Mercurial, CVS, Perforce et TFS.
Outils de construction – IntelliJ prend en charge Java et d’autres outils de construction comme Maven, Gradle et SBT
Décompilateur – IntelliJ est livré avec un décompilateur intégré pour les classes Java. Lorsque vous voulez jeter un coup d’œil à l’intérieur d’une bibliothèque dont vous n’avez pas le code source, vous pouvez le faire sans utiliser de plug-in tiers.
Terminal – IntelliJ fournit un terminal intégré. En fonction de votre plate-forme, vous pouvez travailler avec l’invite de ligne de commande, comme PowerShell ou Bash.
Outils de base de données – IntelliJ fournit des outils de base de données, qui vous permettent de vous connecter à des bases de données actives, d’exécuter des requêtes, de parcourir et de mettre à jour des données.
Serveur d’application – IntelliJ prend en charge les principaux serveurs d’application : Tomcat, JBoss, WebSphere, WebLogic, Glassfish, et bien d’autres. Vous pouvez déployer vos artefacts sur des serveurs d’applications et déboguer les applications déployées dans l’EDI lui-même.
Installation de IntelliJ
Afin d’installer IntelliJ, vous devez tout d’abord le télécharger le site officiel de JetBrains qui propose cet outil, un guide complet et détaillé est accessible sur ce même site lorsque vous allez procéder à l’installation. Le guide est facilement compréhensible donc vous n’aurez aucun mal à le suivre. Toutefois, vous disposeriez uniquement de la personnalisation minimale après cette installation.
Vous pourriez par la suite l’utiliser dans votre métier, que ce soit dans le Big Data en tant que Data Engineer ou bien dans un autre métier relié à la programmation informatique. Et si vous souhaitez vous initier dans cet univers avec cet IDE, vous pouvez prendre des bases dans l’article que nous avons publier sur la programmation informatique.
Les plugins sur intellij
Tout d’abord, un plugin est un logiciel qui ajoute une fonctionnalité spécifique à un programme. Plus de plugins fournissent plus de fonctionnalités à notre application.
Si vous souhaitez donc profiter de toute la puissance d’IntelliJ, il vous faut absolument installer les plugins nécessaires.
Installation d’un plugin avec IntelliJ
Nous allons vous expliquer en détails les étapes qu’il faut suivre afin d’installer un plugin sur IntelliJ pour ensuite compléter les fonctionnalités de bases déjà présentes sur l’IDE.
Pour cela, il vous suffit de suivre les étapes suivantes :
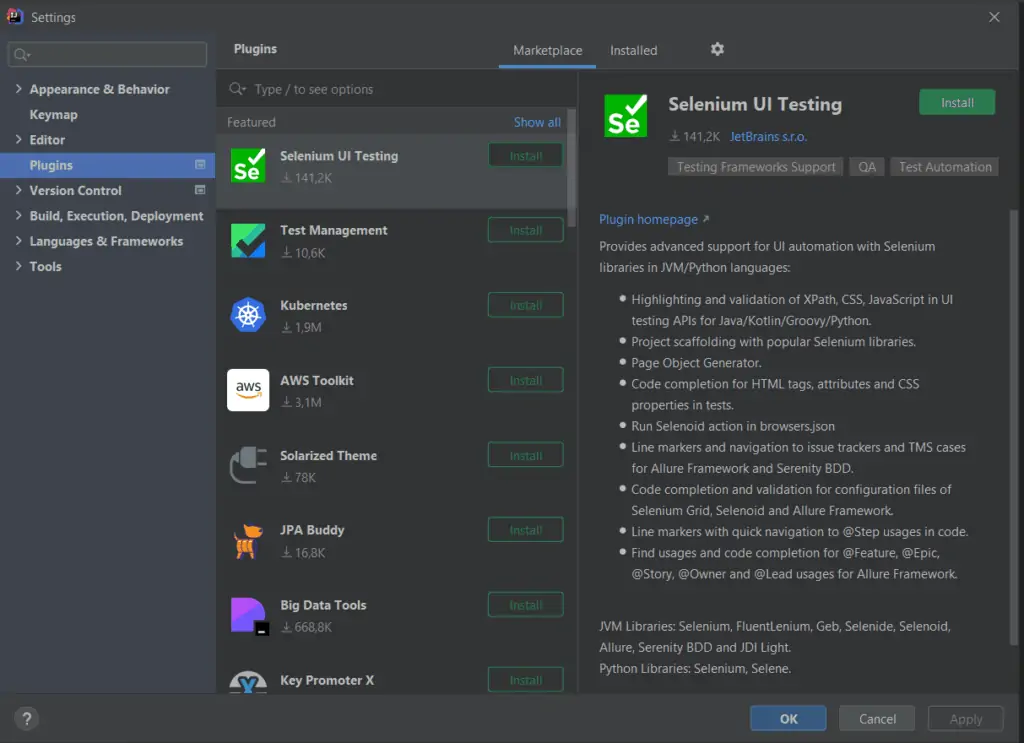
- Allez dans File-> Settings-> Plugins. La fenêtre ci-dessous s’ouvre.
- Dans cette fenêtre, nous pouvons voir tous les plugins installés dans l’IDE. Nous pouvons activer ou désactiver la case à cocher devant les plugins requis.
Catégories de plugins
Dans IntelliJ IDEA, les plugins peuvent être classés dans les catégories suivantes :
- Plugin Bundled. Il est livré avec l’IDE. Ils sont installés et activés par défaut.
- Plugin Repository. Nous pouvons utiliser ce dépôt de plugins en les téléchargeant et en les installant séparément.
Télécharger et installer un plugin repository
Pour télécharger et installer un plugin repository, il faut :
- Aller sur File -> Settings -> Plugins. Une fenêtre s’ouvre.
- Cliquer sur le plugin que vous voulez installer, vous avez sa description dans la deuxième partie de la fenêtre.
Une fois que vous avez séléctionné le plugin que vous voulez :
- Cliquer sur le bouton Install et attendre la fin du téléchargement.
- Cliquer sur Restart IDE et confirmer le redémarrage de l’IDE.
Intellij et son gestionnaire de version
Un gestionnaire de version est un système qui enregistre chaque modification d’un fichier ou d’un ensemble de fichiers dans le temps afin de pouvoir rappeler une version spécifique plus tard. Il nous permet de revenir à l’état antérieur de certains fichiers, à l’état antérieur de tout un projet, de comparer les changements dans le temps, etc. Il peut également nous aider à récupérer facilement nos fichiers perdus. Une fonctionnalité indispensable lorsque nous travaillons sur un projet, notamment sur un projet Big Data.
IntelliJ IDEA IDE supporte de nombreux contrôles de version tels que Git, CVS, TFS, GitHub, Subversion, Mercurial etc. Dans cette section, nous allons discuter du gestionnaire de version le plus connu : Git
Activer le versionning de votre projet
L’intégration de Git à votre projet intelliJ se fait de cette manière :
- Identifiez-vous sur GitHub et créez un nouveau dépôt.
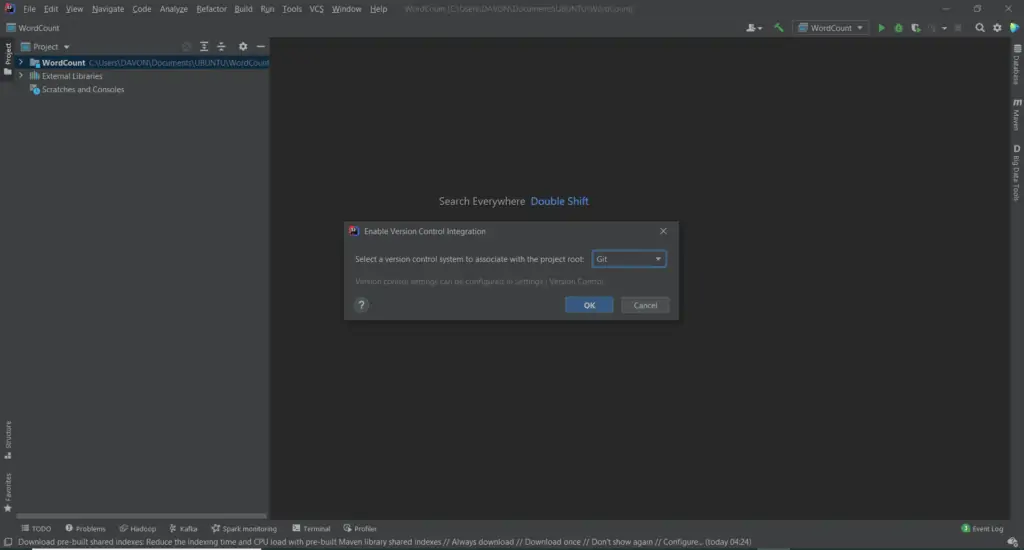
- Cliquez sur onglets VCS -> Enable Version Control Integration. Une boîte de dialogue s’ouvrira.
- Sélectionnez Git dans le menu déroulant.
Cloner un projet depuis un dépôt distant
Maintenant, nous allons comprendre et apprendre le fonctionnement des outils Git et sa terminologie.
Le premier outil que nous allons aborder est donc celui qui permet de cloner un projet depuis un dépôt distant.
Pour ce faire,
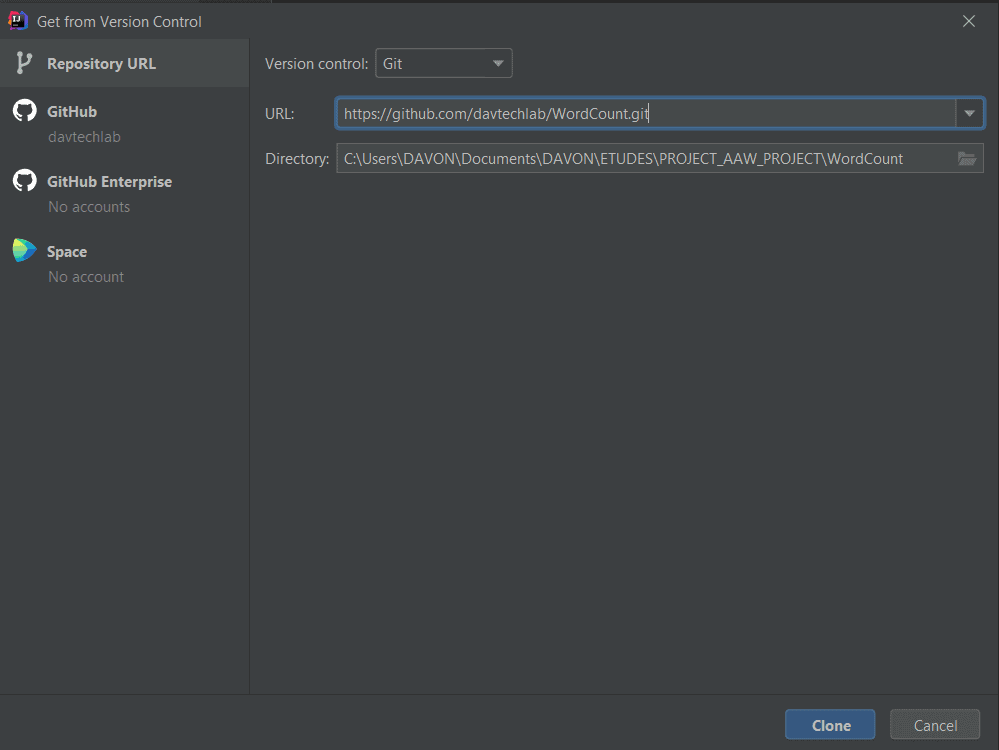
- Allez dans File->New->Project from Version Control. La boîte de dialogue suivante s’ouvre.
- Entrez l’URL du repository et le nom du répertoire et cliquez sur le bouton Clone.
- Après une exécution réussie, le repository sera cloné.
Faire un commit local de son projet
L’action Commit consiste à enregistrer localement notre projet. Pour enregistrer des modifications dans un dépôt local, procédez comme suit :
- Sélectionnez le fichier modifié sous le contrôle de version Git.
- Allez dans Git -> Commit. La boîte de dialogue suivante s’ouvre.
- Dans la zone des fichiers modifiés, nous pouvons voir les fichiers modifiés depuis le dernier commit. Cochez la case des fichiers à commiter.
- Entrez le message de commit et cliquez sur le bouton de Commit.
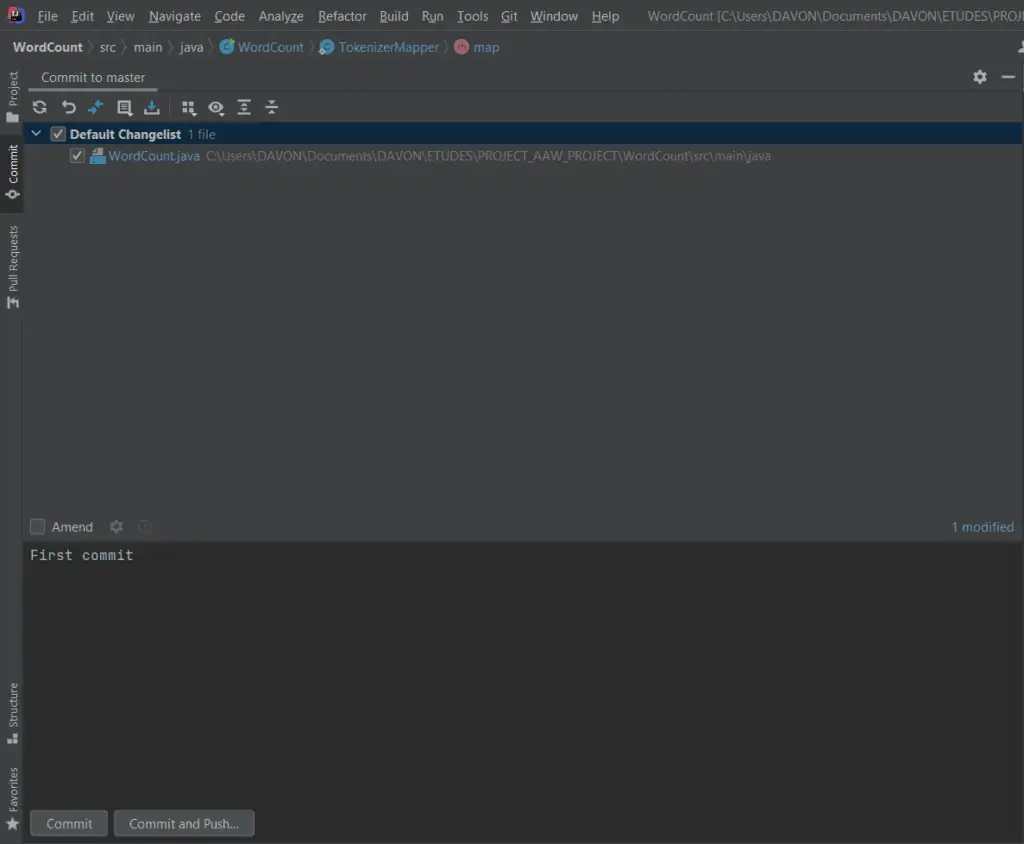
Faire un push vers un dépôt distant
Faire un push consiste à envoyer les changements effectués sur le dépôt local vers le dépôt distant afin qu’ils soient disponibles pour les autres membres de l’équipe. Pour effectuer une action de push, suivez les étapes suivantes :
- Allez sur Git -> Push. La boîte de dialogue s’affiche.
- Nous pouvons voir le commit à pusher, sélectionner le commit et cliquer sur le bouton Push.
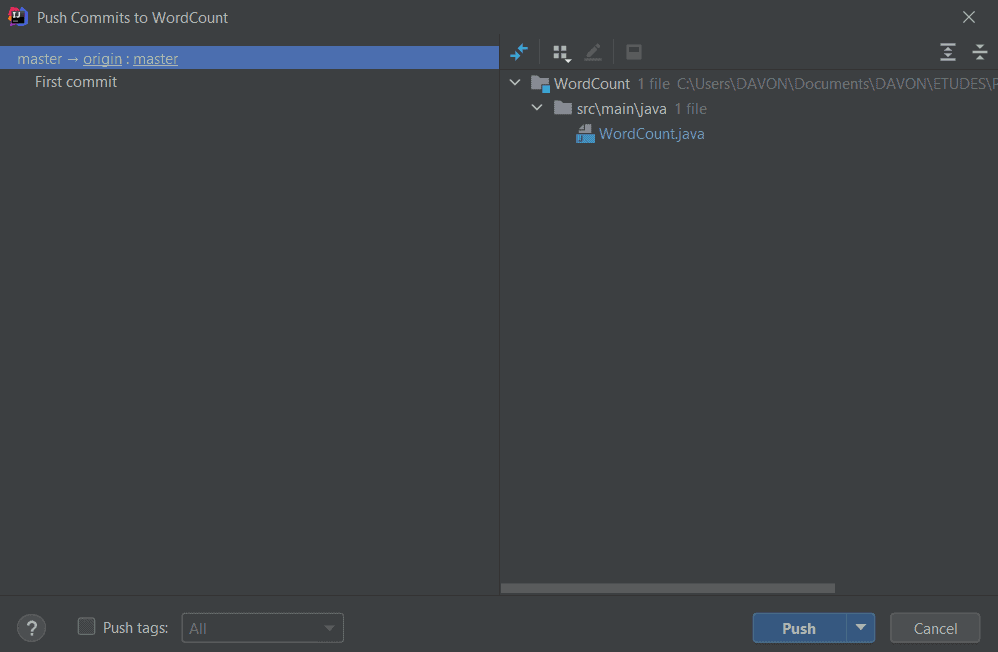
Faire un pull depuis un dépôt distant
Faire un pull consiste à mettre à jour votre projet local avec les mises à jour effectuer sur le dépôt distant. Pour faire un pull procédez de la manière suivante :
- Allez sur Git -> Pull
- Sélectionnez l’option requise.
- Cliquez sur le bouton Pull.
Connexion aux bases de données avec IntelliJ
Lorsque l’on travail sur un projet Big Data, nous serons certainement amené à manipuler des bases de données. Nous allons donc nous intéresser à la façon dont IntelliJ se connecte à ces dernières.
IntelliJ fournit un outil pour gérer les bases de données qui vous permet d’effectuer des opérations CRUD à partir de l’IDE. Il prend en charge les principales bases de données comme MySQL, Oracle, Postgres, SQL server et bien d’autres.
Dans l’un des articles que nous avons publié, nous avons déjà évoqué des manières d’exécuter du SQL dans le Big Data. Plus précisément, nous nous sommes penchés sur les moteurs natifs SQL sur Hadoop. Vous pouvez aller y jeter un coup d’œil si cela vous intéresse d’en apprendre plus.
Dans la suite de cette section nous verrons comment faire communiquer Intellij à une base de données MySQL existante.
Connexion de IntelliJ à une base de données MySQL
Dans cette section, nous allons suivre toutes les étapes pour que l’on puisse disposer d’une base de données.
Création de la base de données
Créer une base de données MySQL nomée db_test avec votre logiciel favori (Xammp, Wampp, mysql.exe).
Connexion à la base de données
Suivez les étapes suivantes pour se connecter à une base données MySQL :
- Aller sur View → Tool Windows → Database.
- Cliquer sur l’icône « + » et sélectionnez Data Source → MySQL.
- Remplir les informations demandées et cliquez sur and, puis cliquez sur le bouton Test Connection.
- Si tout se passe bien, vous verrez apparaître un check vert comme dans l’image ci-dessus.
- Cliquer sur Apply puis sur OK pour enregistrer la data source.
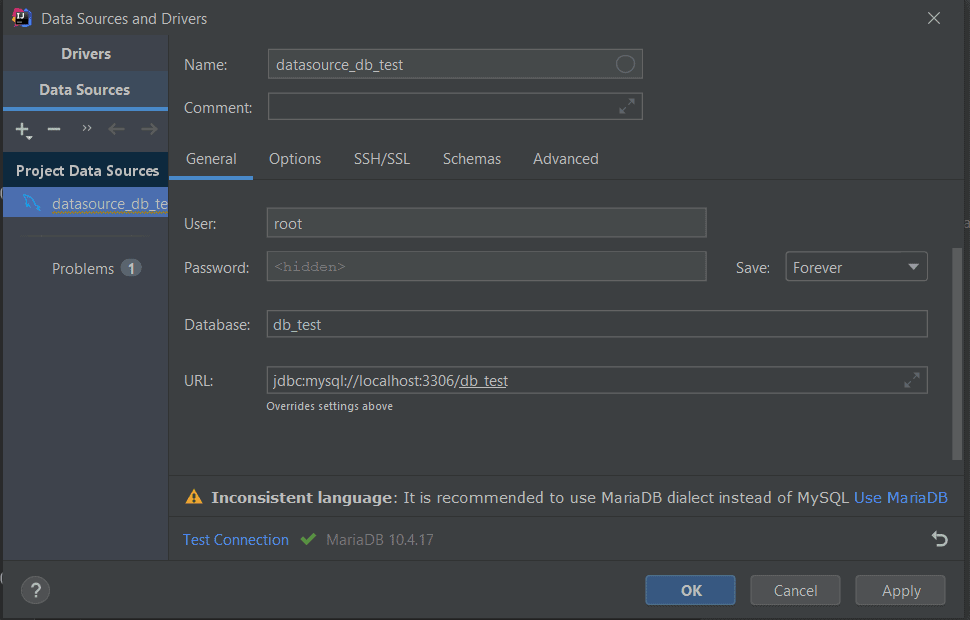
Création d’une table
Suivez les étapes suivantes pour créer une nouvelle table
- Faire un clic droit sur db_test et sélectionnez New -> Table
- Une nouvelle fenêtre apparaît. Définissez le nom de la table, ajouter les différentes colonnes etc…
- Cliquer sur le bouton Execute.
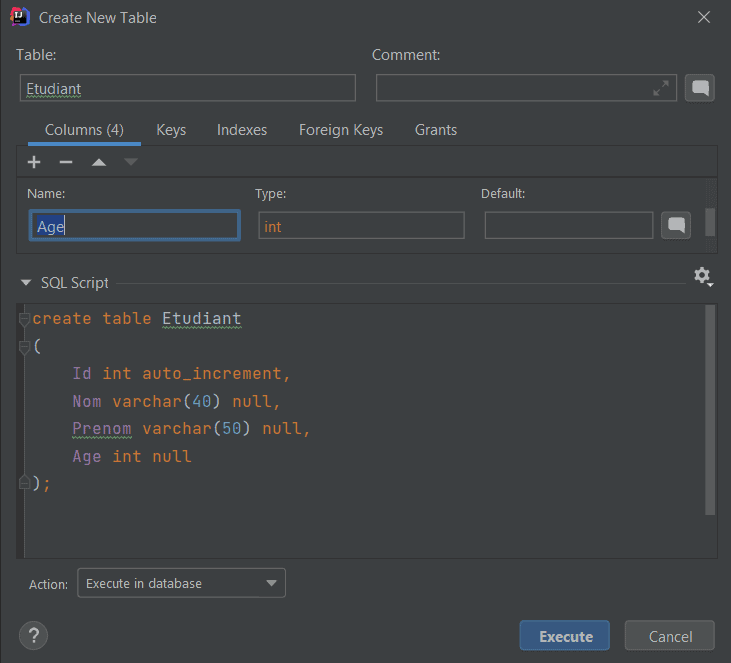
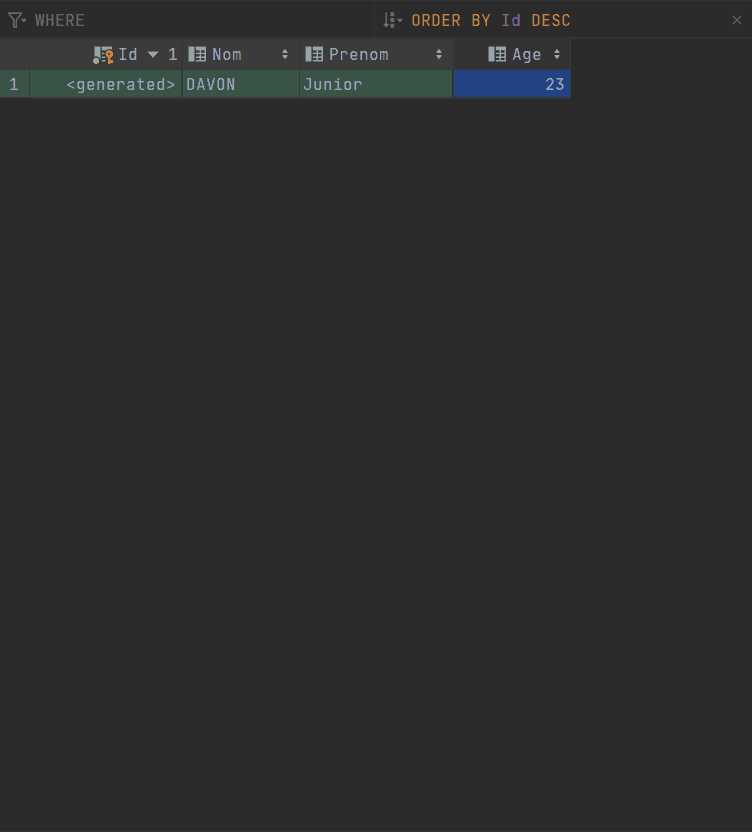
Insertion des données
Suivez ces étapes pour insérer des données dans votre base de données :
- Sélectionnez la table.
- La table s’ouvrira dans une nouvelle fenêtre.
- Faites un clic droit dans la fenêtre.
- Cliquer sur Add Row.
- Remplissez la ligne.
- Cliquer sur le bouton Submit (icône de flêche en haut).
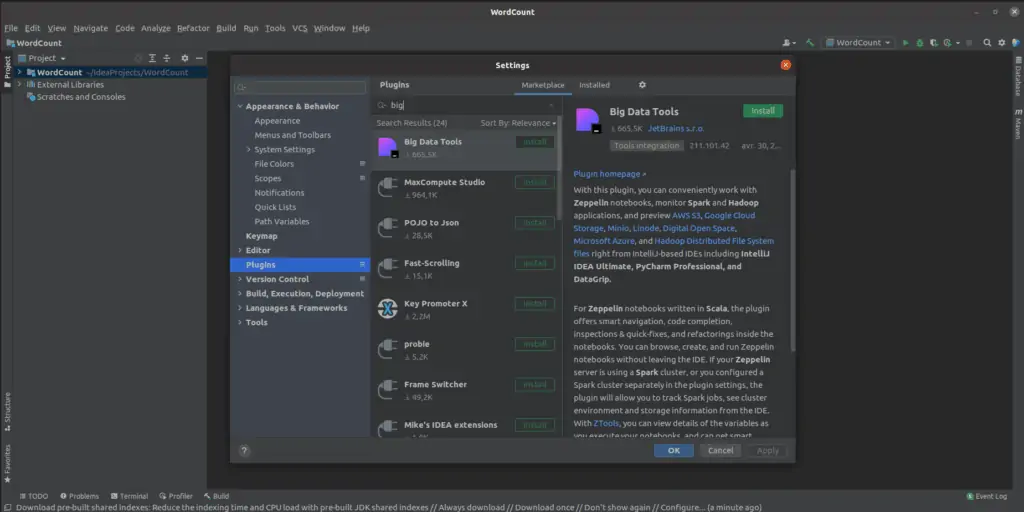
L’extension Big Data tools d’Intellij

Le plugin Big Data Tools est disponible pour IntelliJ IDEA 2019.2 et les versions ultérieures. Il fournit des fonctionnalités spécifiques pour monitorer et traiter les données avec Zeppelin, AWS S3, Spark, Google Cloud Storage, Minio, Linode, Digital Open Spaces, Microsoft Azure et Hadoop Distributed File System (HDFS).
Nous avons d’ailleurs un article complet qui parle de ces framework, notamment de Hadoop et de Spark.
Pour les notebooks Zeppelin écrits en Scala, le plugin offre une navigation intelligente, la complétion de code, des inspections et des corrections rapides, et des remaniements à l’intérieur des carnets. Vous pouvez parcourir, créer et exécuter les notebooks Zeppelin sans quitter l’IDE. Si votre serveur Zeppelin utilise un cluster Spark, ou si vous avez configuré un cluster Spark séparément dans les paramètres du plugin, le plugin vous permettra de suivre les Jobs Spark, de voir l’environnement du cluster et les informations de stockage depuis l’IDE. Avec ZTools, vous pouvez voir les détails des variables au fur et à mesure que vous exécutez vos notebooks, et vous pouvez obtenir une complétion intelligente pour les colonnes des data frames en SQL et Scala.
Vous pouvez également charger, télécharger et prévisualiser de gros fichiers structurés sous forme de tableaux, notamment aux formats CVS, Parquet, AVRO et ORC.
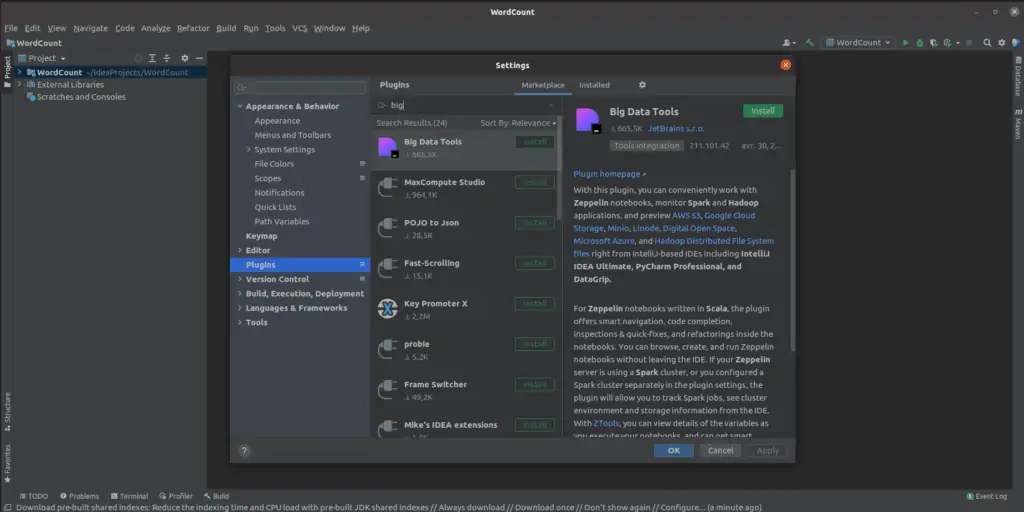
Pour installer le plugin Big Data Tools veuillez sélectionnez File->Settings->Plugins, rechercher le plugin Big Data Tools et cliquer sur installer.
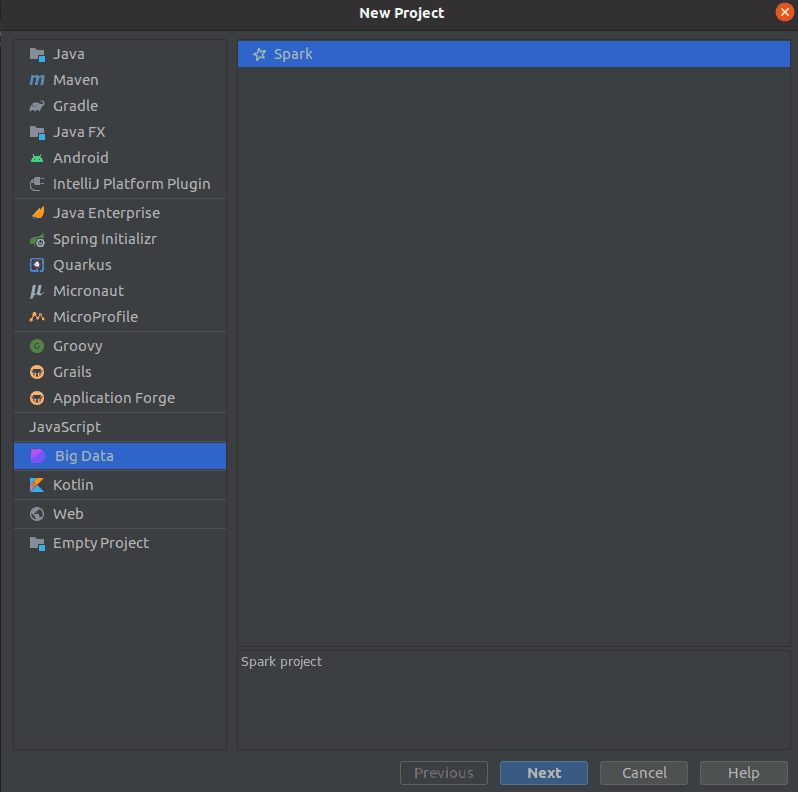
Le plugin Big Data tools de Intellij vous permet de créer un projet Spark avec toute la configuration minimale pour son exécution. Ce qui facilitera grandement le travail lors de la réalisation d’un projet Big Data.
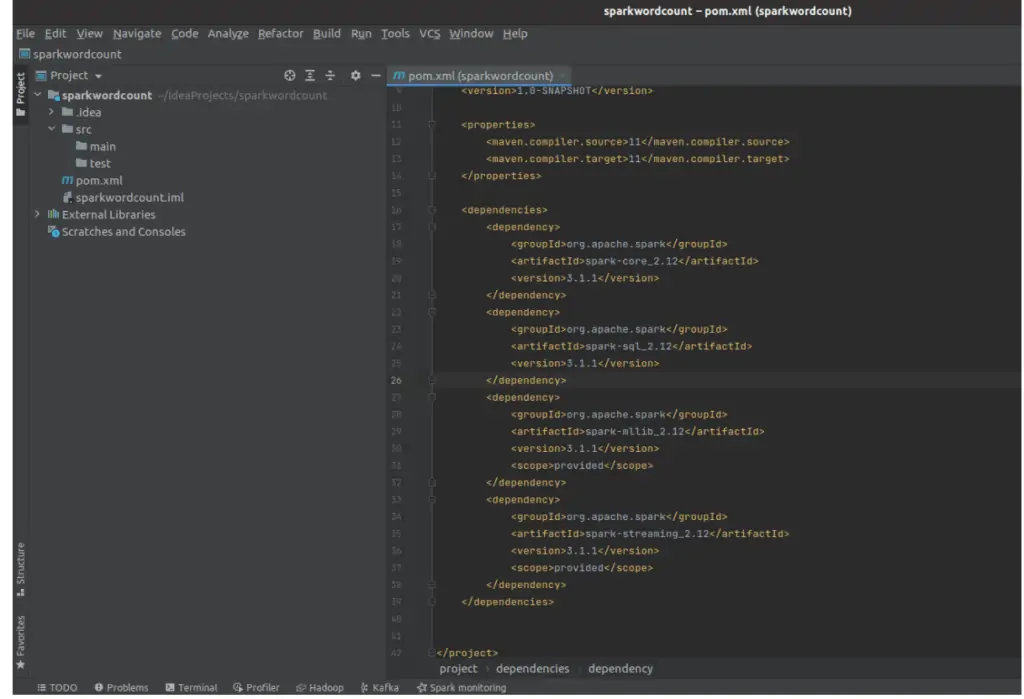
Créer un projet Hadoop avec Intellij
Dans cette partie, nous allons voir comment vous pouvez écrire et tester votre programme Hadoop avec Maven facilement sur IntelliJ sans configurer l’environnement Hadoop sur votre machine ou utiliser un cluster.
Cependant, il existe une formation complète sur l’écosystème Hadoop si vous souhaitez approfondir le sujet.
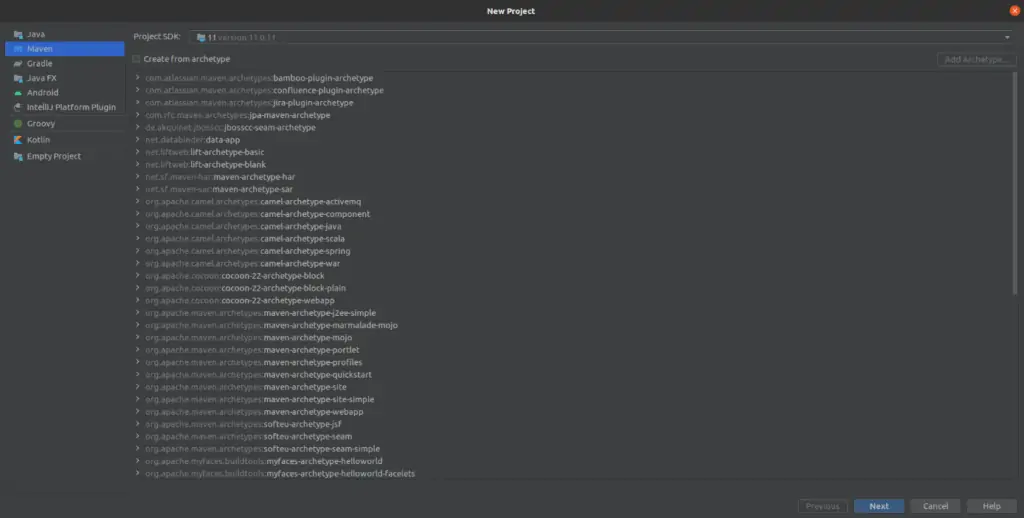
Étape #1 : Créer un nouveau projet
Cliquez sur créer un nouveau projet et choisissez Maven puis cliquez sur Next.
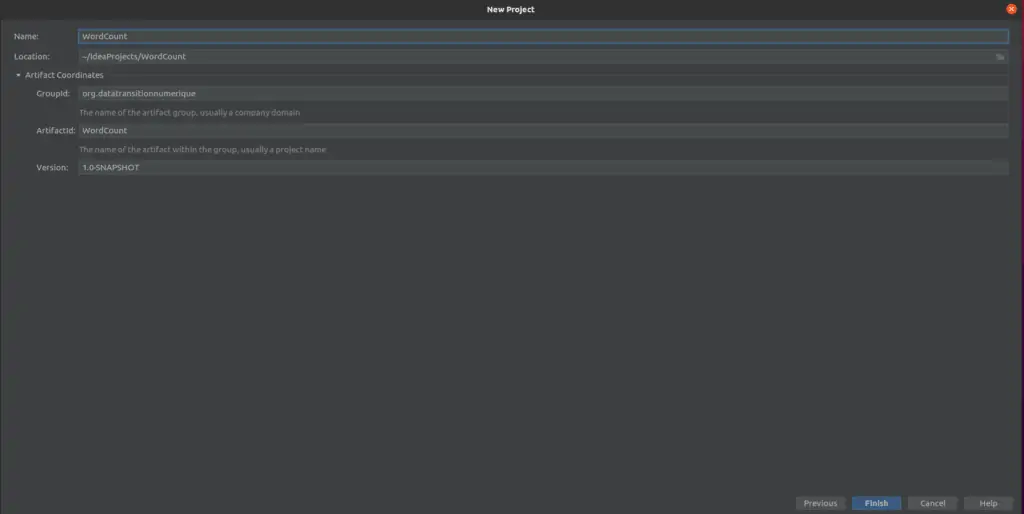
Définissez votre nom de projet, l’emplacement du projet, groupId, et artifactId. Ne modifiez pas la version et cliquez sur Finish.
Maintenant nous sommes prêts à configurer les dépendances de notre projet
Étape #2 : Configuration des dépendances
Ouvrez le fichier pom.xml. Dans votre fichier pom.xml, posez les blocs suivants avant la balise </project> :
11
11
apache
http://maven.apache.org
org.apache.hadoop
hadoop-core
1.2.1
org.apache.hadoop
hadoop-common
3.2.0
Le fichier pom.xml final devrait ressembler à ce qui suit :
4.0.0
com.datatransitionnumerique
WordCount
1.0-SNAPSHOT
11
11
apache
http://maven.apache.org
org.apache.hadoop
hadoop-core
1.2.1
org.apache.hadoop
hadoop-common
3.2.0
Faites un re-load du fichier pom.xml pour télécharger les dépendances.
Étape #3 : création d’une classe WordCount
Allez sur src -> main ->java et faites un clic droit pour créer une nouvelle classe Java.
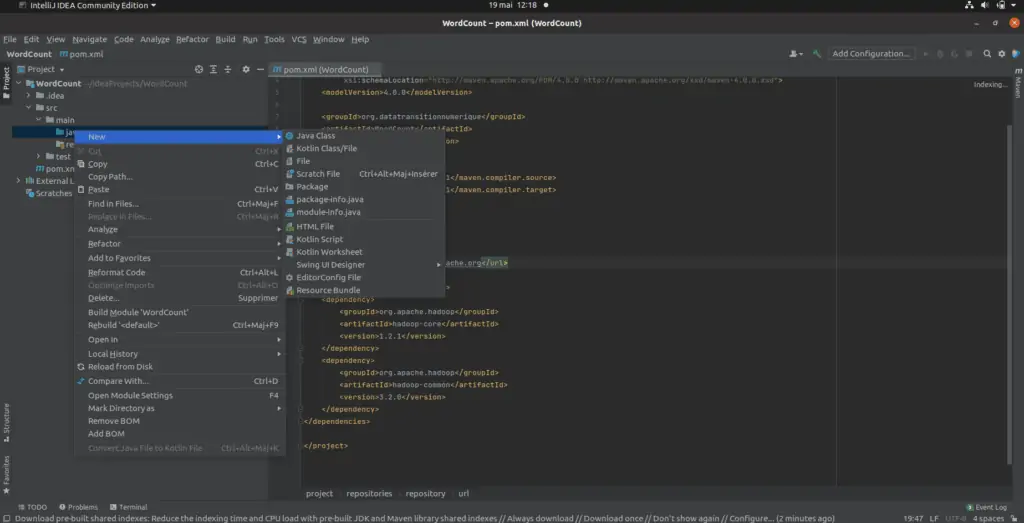
Nommez la classe et cliquez et entrez.
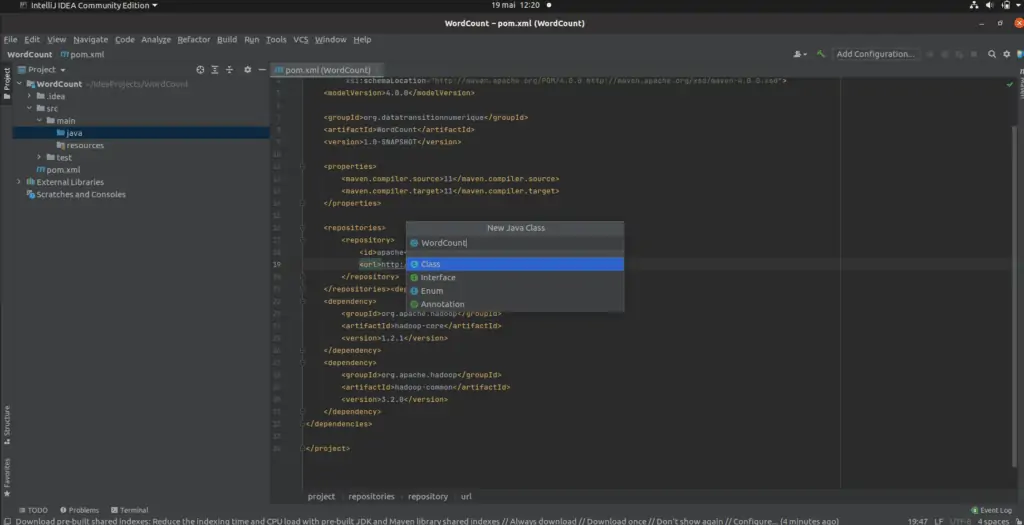
Collez le code Java suivant dans votre classe WordCount :
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class TokenizerMapper
extends Mapper {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}Le code de la classe WordCount comprend la méthode principale, la classe map et la classe reduce. Il scanne tous les fichiers texte dans le dossier défini par le premier argument, et réduit les fréquences de tous les mots dans un dossier défini par le second argument.
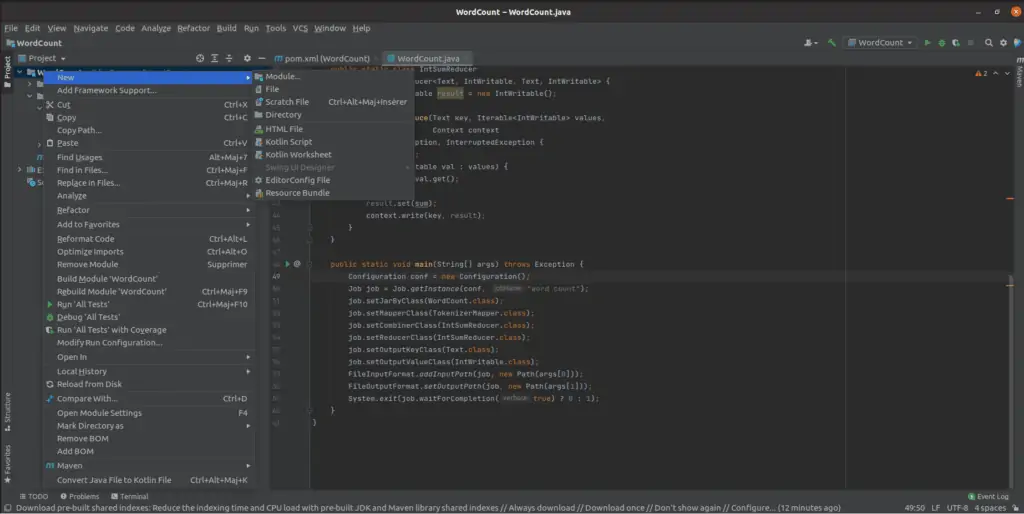
Étape #4 : nous sommes presque prêts à exécuter le programme !
Nous devons d’abord créer notre fichier texte d’entrée. Dans votre package de projet, créez un nouveau dossier et nommez-le « input ». Dans le dossier input, créez votre fichier txt ou faites-en glisser un si vous l’avez déjà.
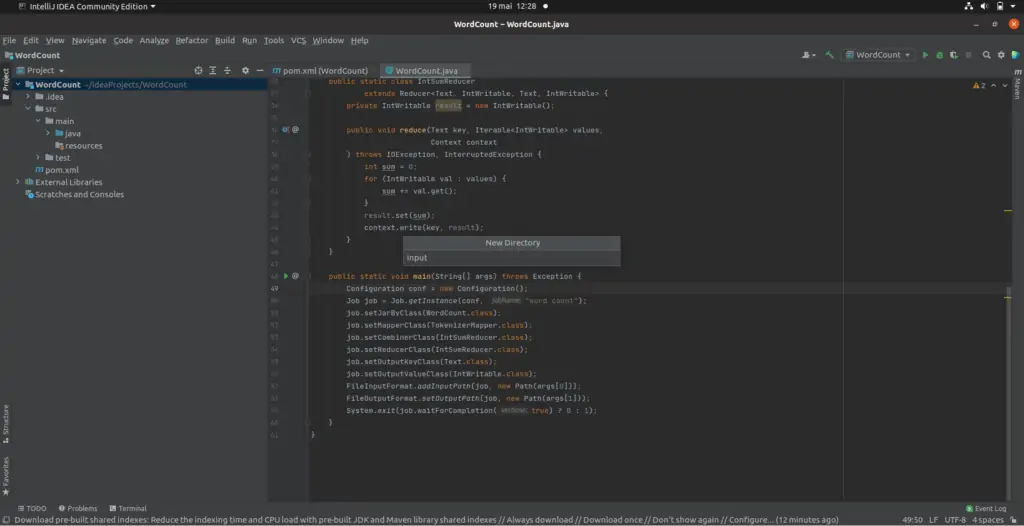
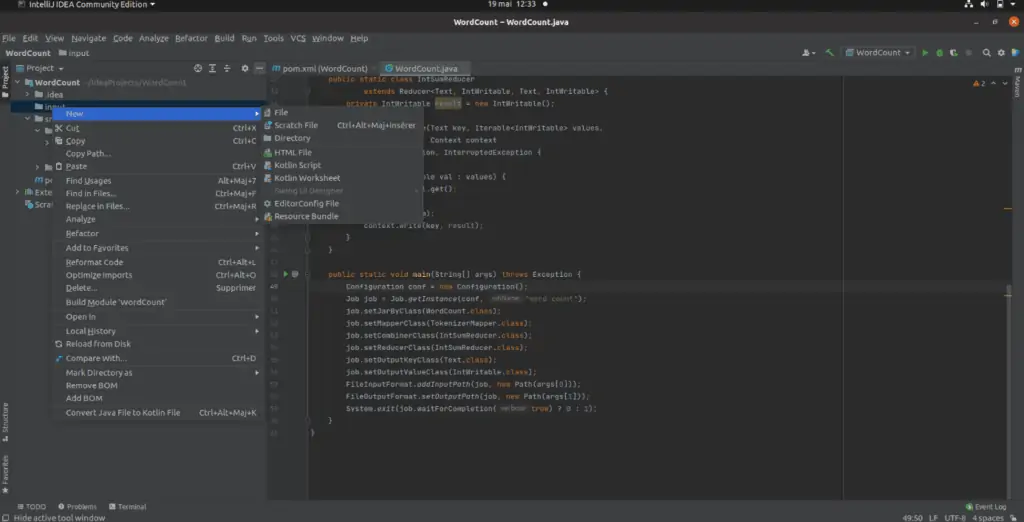
Vous devez par la suite écrire dans le fichier crée le texte suivant :
Le MapReduce est d’abord et avant tout un modèle algorithmique, c’est-à-dire une manière de penser le découpage d’un problème en tâches. Il consiste à découper le traitement d’un fichier de données en tâches indépendantes en suivant 2 phases : une phase Map, une et une phase Reduce.L’utilisateur spécifie une fonction de hachage Map qui transforme les données d’entrée en paires de clés/valeurs, et une fonction de hachage Reduce qui agrège toutes les valeurs associées à la même clé. Une phase intermédiaire entre le Map et le Reduce, appelée shuffle trie les paires de clés/valeurs générées par clé.
D’ailleurs, Pour mieux comprendre cette méthode, nous vous invitons à lire l’article destiné à la méthode MapReduce.
Après cela, cliquez sur Run -> Edit -> Configuration pour définir les arguments de notre projet.
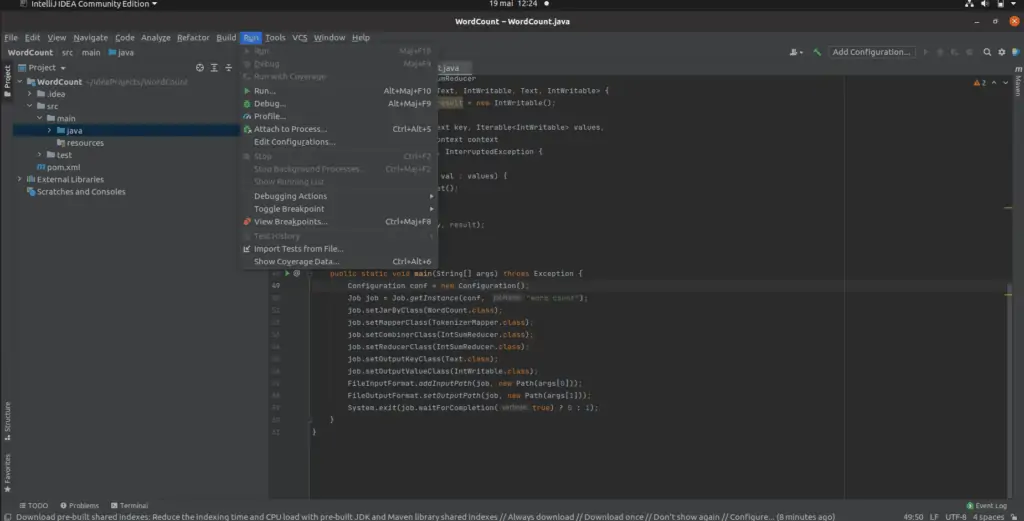
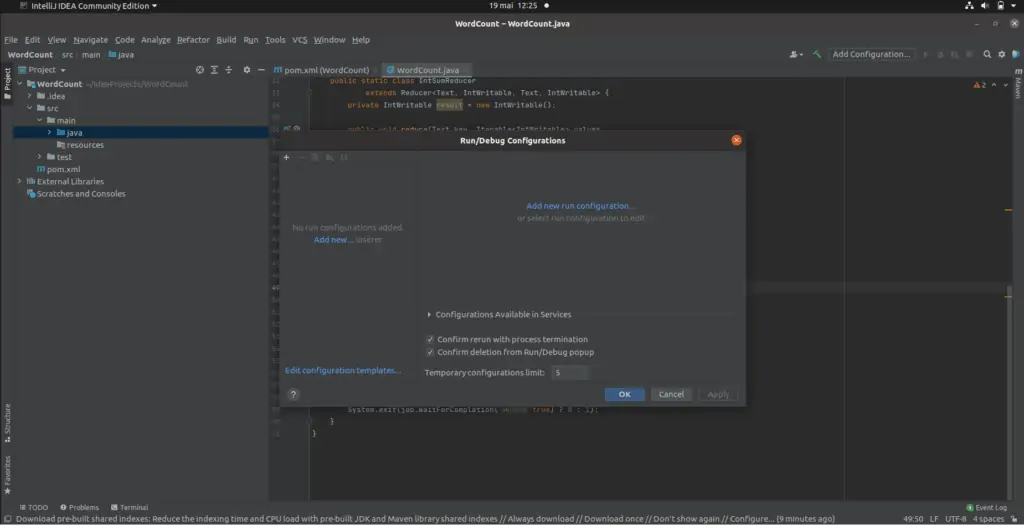
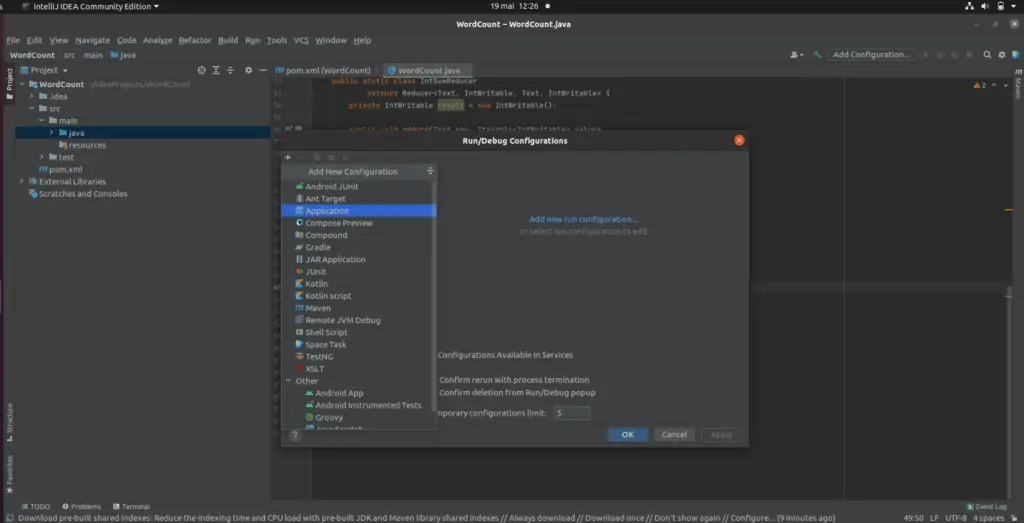
Ajoutez une nouvelle configuration d’application en sélectionnant « + » puis Application.
Définissez la classe principale comme WordCount, et les arguments du programme comme input output. Ceci permet au programme de lire le dossier input et de sauvegarder le résultat dans le dossier output. Ne créez pas le dossier output, car Hadoop le créera automatiquement. Si le dossier existe, Hadoop lèvera une exception. Quand vous avez terminé, cliquez sur Apply puis sur OK.
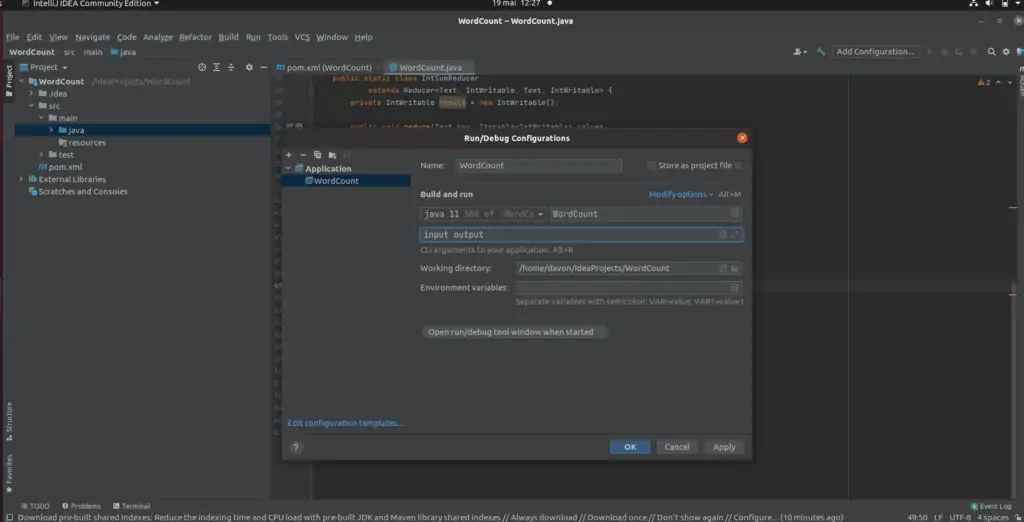
Étape #5 : maintenant, nous sommes prêts à exécuter notre programme !
Pour ce faire, sélectionnez Run -> Run ‘WordCount’ pour exécuter le programme Hadoop. Si vous réexécutez le programme, supprimez le dossier de « output » avant.
Un dossier « output » apparaît. À chaque exécution, vos résultats sont enregistrés dans output→part-r-00000.
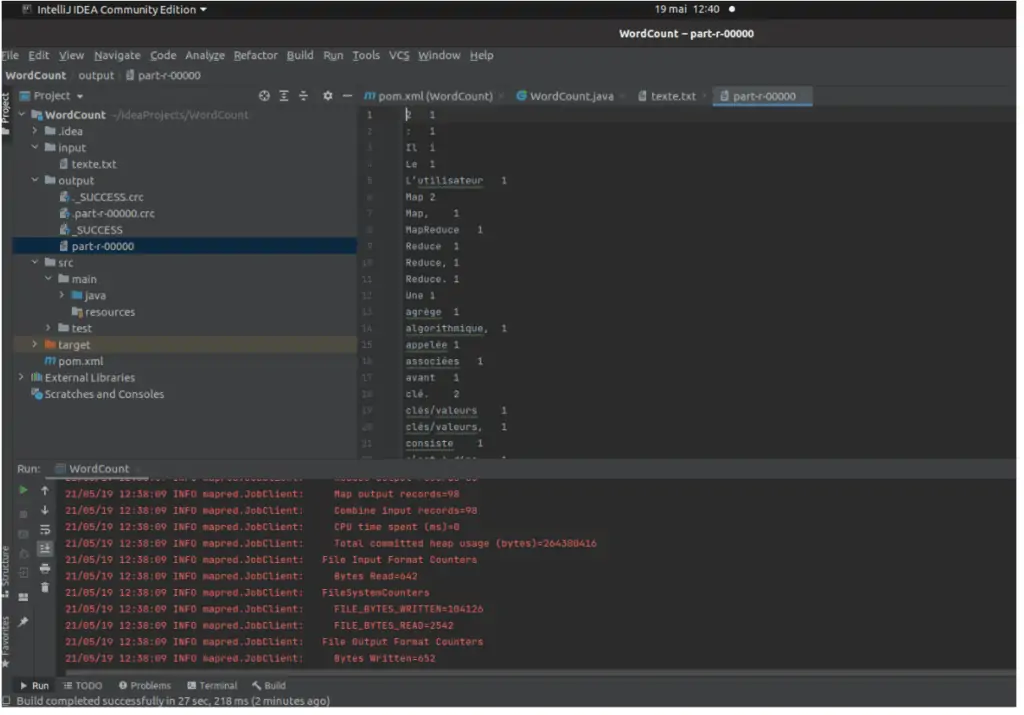
Problème sur Windows
Vous pouvez rencontrer cette en exécutant le programme Hadoop sous Windows :
ERROR security.UserGroupInformation : PriviledgedActionException as ...Ceci est dû au fait que la bibliothèque Hadoop essaie d’accéder à un chemin spécifique à Unix (par exemple /tmp), et essaie d’exécuter certaines fonctions spécifiques à Unix (par exemple définir la permission du dossier à 0700). Il existe quelques solutions possibles, par exemple, remplacer la configuration d’Hadoop pour définir le bon dossier temporaire, ou appliquer des correctifs à la bibliothèque Hadoop pour contourner les fonctions spécifiques à Unix. Cependant, il est toujours fortement recommandé d’exécuter un programme Hadoop sur Linux ou Mac OS.
Vous savez maintenant pourquoi faut-il utiliser IntelliJ pour le Big Data et comment profiter de toutes ses fonctionnalités. En effet, grâce aux panels d’outils que cet IDE fournit, le travail des personnes œuvrant dans le Big Data, notamment celui du Data Engineer, est plus efficace. Si vous faites partie de ces personnes ou que vous souhaitez intégrer leur rang, vous pouvez donc apprivoiser cet IDE sans aucun souci si vous avez suivi cette chronique du début à la fin.



Bonjour Juvénal,
D’abord merci pour le tuto.
Je voudrais savoir quel est l’édition de IntelliJ que tu as utilisé?
Car j’ai installé « IntelliJ IDEA Community Edition » et quand je cherche plugin « Big Data Tools », rien ne s’affiche.
Merci pour ton retour,
Bonjour Ibrahim,
C’est dans l’éditions « entreprise » que le plugin Big Data tool est disponible.
Normalement, la version « Community » est largement suffisante pour les devs, mais ce plugin particulièrement est « payant ». Tu peux télécharger la version entreprise et tester pendant 14 jours.
Cordialement,
Juvénal