citation Tutoriel HBase : « Faire du NoSQL c’est juste faire des choix intelligents »
Avec toute la volumétrie des données dont on dispose aujourd’hui et toutes leurs caractéristiques, c’est impossible de penser « Gestion de données » tel qu’on l’a fait dans le passé, c’est-à-dire centraliser le stockage des données sur un serveur et centraliser le traitement de ces données sur un SGBDR. Dans l’ère du Big Data, l’approche appropriée consiste à distribuer le stockage des données et de paralléliser leur traitement sur les nœuds d’un cluster d’ordinateurs. Les moteurs de bases de données relationnelles ne sont pas capables d’assurer la cohérence des données sur plusieurs nœuds d’un cluster. Leur capacité de distribution maximale est estimée à 5 nœuds, ce qui est largement insuffisant pour répondre aux exigences de volumétrie des données. Pour dépasser ces limites, de nouveaux SGBD dit « NoSQL » ont vu le jour. La particularité de ceux-ci est qu’ils n’imposent pas de structure particulière aux données, ils relâchent les contraintes qui empêchent les SGBDR de distribuer le stockage des données et sont linéairement scalables. HBase fait partie de cette catégorie de SGBD. Plus précisément, HBase fait partie de la catégorie de SGBD orienté-colonne, et est l’un des tous premiers SGBD NoSQL à large échelle mis sur pied. Crée en fin d’année 2006 par Chad Walters et Jim Kellerman, HBase a rejoint l’écosystème Hadoop en octobre 2007 et en Juin 2010, il est devenu un projet prioritaire de la fondation Apache. HBase est de plus en plus utilisé dans beaucoup d’entreprises qui gèrent des données même de volumétrie modeste, cela à cause de sa structure familière aux utilisateurs métier et à cause de sa grande capacité de gestion de données. A cause de l’exigence croissante des entreprises demandant aux développeurs et consultants d’avoir des connaissances sur HBase, nous allons mettre un point d’honneur à son étude rigoureuse dans ce tutoriel. Nous n’allons pas juste nous limiter à expliquer les principes de fonctionnement d’HBase, mais nous allons vous aider à développer des compétences opérationnelles dessus. Ainsi, à la fin du tutoriel, vous serez capables d’utiliser HBase.
1. CONCEPT DE BASE DE HBASE
HBase fait partie d’une catégorie de SGBD NoSQL appelée les SGBD orientés-colonne. Dans cette catégorie de SGBD, la notion de base de données et la façon dont les données sont stockées sont très différentes de ce que vous avez l’habitude d’utiliser jusqu’ici (les SGBDR), même si visuellement ils peuvent être similaires. Dans cette partie, nous allons clarifier ce qu’est HBase et nous allons expliquer ce qu’HBase entend par base de données.
1.1. Définition d’HBase
Avant de donner la définition d’HBase, commençons par dire ce qu’il n’est pas : HBase n’est pas un SGBD au sens strict du terme. Il n’implémente pas un schéma de base de données modélisée à l’aide d’un MCD, et ne fournit pas les fonctionnalités de gestion de ce schéma telle que le typage des données, les mécanismes de clés primaires, de clés étrangères, d’indexes, le langage d’interrogation de données, ou encore la gestion des transactions. A la place de « système de gestion de base de données », HBase est plus ce qu’on pourrait qualifier d’ « entrepôt de stockage de données ». Là où les SGBD assurent à la fois le stockage et le traitement des données, HBase lui est plus spécialisé sur le stockage des données. Il utilise des modèles de calcul externe pour leur requêtage. HBase est un SGBD distribué, orienté-colonne qui fournit l’accès en temps réel aussi bien en lecture qu’en écriture aux données stockées sur le HDFS. Là où le HDFS fournit un accès séquentiel aux données en batch, non-approprié pour des problématiques d’accès rapide à la donnée comme le Streaming, HBase couvre ces lacunes et offre un accès rapide aux données stockées sur le HDFS. Il faut comprendre par la que HBase est perçu par le HDFS comme un client à qui il fournit les données. HBase a été conçu pour :
- ne fonctionner que sur un cluster Hadoop ;
- être linéairement scalable, c’est-à-dire que supporte l’ajout de nœuds au cluster ;
- stocker de très grosses volumétries de données épaves, c’est-à-dire des données à structure irrégulière, avec plein de valeurs nulles comme les matrices creuses en Algèbre. Nous y reviendrons plus bas ;
- fournir un accès en temps réel à cette grosse volumétrie de données aussi bien pour les opérations de lecture que d’écriture sur le HDFS ;
- s’appuyer sur des modèles de calculs distribués tels que le MapReduce (et donc tous ses langages d’abstraction tels que Hive, Pig, Cascading,…) pour l’exploitation de ses données ;
En réalité, HBase est l’implémentation Hadoop du projet Google Big Table. Big Table est le premier SGBD distribué développé par Google qui s’appuie sur le GFS (Google File System) dont le HDFS est l’implémentation.
| Attention ! Il n’y a théoriquement aucune raison qui puisse laisser penser que HBase ne puisse pas utiliser un autre système de fichier distribué que le HDFS. |
1.2. La Base de Données en HBase
La particularité de HBase est qu’il n’implémente pas de concept de « base de données ». Par conséquent la manière dont on concevait les bases de données dans les approches traditionnelles ne peut pas être utilisée avec les approches NoSQL en général et avec HBase en particulier. Nous insistons là-dessus parce que dans notre travail professionnel quotidien, nous avons vu beaucoup d’entreprises commencer leur projet de migration vers HBase avec la conception d’un MCD. Ceci vient surement du fait que dans le passé, et jusqu’à présent, lorsqu’on veut concevoir une base de données, on commence par concevoir un MCD, qui sera par la suite transformé en un modèle relationnel (MRD) et finalement en script SQL qui sera exécuté par le moteur du SGBDR. Si vous exercez le métier de consultant, d’ingénieur, d’analyse de base de données ou tout autre profession relative à la construction des bases de données, ou si vous êtes étudiants, alors il y’a de fortes chances que vous ayez été formés à débuter la création d’une base de données par un MCD. Cette façon de faire est devenu normal, voir même de l’ordre du réflexe. Mais avec le NoSQL en général et HBase en particulier, tout change : premièrement le concept de base de données n’est pas le même que dans les SGBDR, en plus il varie selon les catégories de SGBD NoSQL, et deuxièmement vous ne commencez pas la conception de votre « base de données » par un MCD. Nous allons voir plus bas comment modéliser une base de données en HBase. Pour l’heure, vous devez garder à l’esprit que Dans le NoSQL, le schéma de « base de données » que vous allez concevoir a pour but d’assurer la distribution du stockage et faciliter l’accès des données dans un cluster pour les traitements parallèles. Gardez bien cela à l’esprit !
Le concept de base de données en HBase est la table HBase. En d’autres termes, développer et modéliser une base de données en HBase revient à implémenter une ou plusieurs tables HBase. Une table HBase est un tableau multidimensionnel de données distribué et persisté sur le HDFS sous forme de fichiers spécifiques appelés HFiles. Voici les dimensions qui forment ce tableau multidimensionnel :
- La première dimension c’est la « row key » (clé de ligne). Chaque ligne du tableau HBase est identifiée de façon unique par une clé « row key ». Attention, bien que similaire à une clé primaire dans une table relationnelle, la différence ici est que la row key n’est pas nécessairement une colonne parmi l’ensemble des colonnes désignée comme telle par le développeur, c’est une colonne interne à la structure de la table HBase, similaire à la colonne de numéros qui identifient chaque ligne d’une feuille de calcul Excel. Par contre, vous avez la responsabilité de définir non pas la colonne qui va servir de row key, mais la structure des données qui vont y être générées. Nous allons vous montrer comment faire plus bas ;
- La deuxième dimension est la famille de colonne (column family), d’où HBase tire son nom de SGBD orienté-colonne. les familles de colonnes représentent les valeurs d’un ensemble de colonnes physiquement colocataires c’est-à-dire physiquement sérialisées (stockées) dans le même ficher. Chaque famille de colonnes est persistée dans un HFile séparé, et chaque HFile possède son propre jeu de paramètres de configuration. Cette dimension est très importante, car elle définit la façon dont les données sont persistées et accédées. A cet effet, lors de la modélisation de la table HBase, vous veillerez particulièrement à placer les colonnes les plus utilisées dans la même famille de colonnes. Petite remarque, les colonnes qui constituent une famille de colonne n’entretiennent pas de lien particulier, elles sont indépendantes et c’est vous qui décidez des critères sur lesquels vous allez regrouper les colonnes. De plus, il n’y’a théoriquement pas de limites au nombre de familles de colonnes qui peuvent être créées et au nombre de colonnes dans chaque famille. Une fois encore, tout dépend des besoins du client, de vous le créateur de la table HBase et de la capacité du cluster ;
- La troisième dimension est la colonne (column qualifier). Une colonne c’est l’adresse d’une série de données dans une famille de colonnes. Vous pouvez voir les colonnes HBase comme les colonnes d’un tableau ou comme les colonnes d’une feuille de calcul Excel. Ils désignent simplement les données des lignes de la même adresse dans une famille de colonne. Cette adresse porte un label et c’est ce label qu’on qualifie de colonne ou de qualificateur de colonne. Les colonnes sont dynamiques et peuvent être différentes d’une ligne à une autre, en d’autres termes, des valeurs peuvent être manquantes pour la ligne d’une colonne (NULL dans les bases de données traditionnelles), auquel cas la colonne n’est pas créé pour la ligne en question. C’est cette propriété (le dynamisme des colonnes) qui lui permette de stocker des données éparses ;
 |
A la différence des colonnes, les familles de colonnes elles, sont statiques, c’est-à-dire définies à la création de la table et fixe tout au long de leur vie, là où les colonnes elles sont dynamiques, c’est-à-dire ne sont pas définies lors de la création de la table, mais sont dynamiquement créés lors des opérations d’écriture/mise à jour de la donnée dans la colonne de la ligne. Ainsi, HBase traite les colonnes comme une table dynamique de paires de clé/valeur. Comme résultat, chaque ligne/famille de colonnes peut contenir des jeux arbitraires de colonnes. La figure ci-après illustre la propriété dynamique des colonnes. |
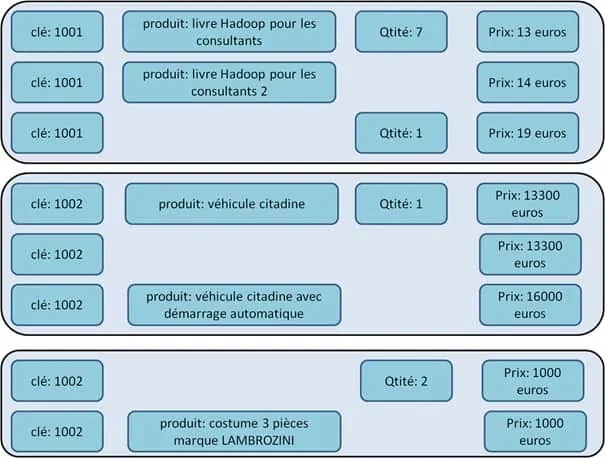
Figure 1 : cette figure illustre le dynamise des colonnes dans HBase. Les colonnes sont créées à l’ajout de donnée dans la table. Attention, notez que l’absence d’une valeur dans une colonne ne signifie pas qu’elle est nulle. Cela signifie qu’elle n’existe pour ce TimeStamp. C’est cette caractéristique qui permet à HBase de gérer les données épaves.
- la quatrième dimension c’est la cellule (cell) ou valeur (pour faire référence au contenu de la cellule). Une cellule HBase est l’intersection entre une row key, une famille de colonne et une colonne. Les données sont stockées dans les cellules. Attention ! À la différence des cellules dans le sens Excel du terme, les cellules HBase ne stockent pas uniquement les données textuelles ou des nombres. vous pouvez stocker dans chaque cellule, un PDF, une vidéo, une image, un texte, bref n’importe quel type de données numérique. Elles y sont stockées sous forme de type générique Byte [] , ainsi, vous n’avez pas à typer les colonnes en HBase. Dans la figure 33 ci-dessus, vous pouvez voir chaque cellule HBase ;
- La dernière dimension est le TimeStamp. Il faut savoir qu’HBase ne fait pas de différence entre les ajouts de lignes dans la table (opération d’écriture) et leur mise à jour (opération de modification d’une ligne). Tout comme dans le HDFS et dans un Data Warehouse, chaque opération de mise à jour est un ajout d’une nouvelle version de la même ligne de données. La distinction de versions d’une même ligne se fait à l’aide d’une valeur horodatée appelée TimeStamp. Ce TimeStamp c’est la date à la milliseconde près à laquelle la mise à jour a été effectuée. Pour les habitués de la modélisation des Data Warehouse, le TimeStamp correspond à une dimension SCD (Slowly Changing Dimension). Par défaut, HBase stocke les 3 dernières versions d’une valeur de colonne (tout en supprimant automatiquement les anciennes versions). La profondeur du « Versioning » peut être contrôlée lors de la création de la table.
|
Attention ! L’horodatage est propre à chaque cellule, pas globale à la ligne. En d’autres termes, chaque cellule est horodatée du TimeStamp du moment auquel elle a été créée. Notez également que physiquement le concept de « ligne » n’existe pas en HBase, c’est pourquoi le TimeStamp n’est pas propre à toute la ligne. La row key n’identifie pas les lignes, mais la combinaison « famille, colonne, cellule, TimeStamp ». Chaque cellule horodatée est indépendante des cellules des autres colonnes, même si elles sont insérées dans la table HBase au même moment. |
La figure suivante illustre le tableau multidimensionnel qui forme la structure logique d’une table HBase.
| ROW KEY | TIMESTAMP | COLUMN FAMILY | COLUMN NAME | VALUE |
| Clé de la ligne | Date de création ou de mise à jour de la ligne | Famille de colonne | Nom de la colonne | Valeur ou donnée stockée dans la cellule |
Figure 2 : structure logique d’une table HBase
Une autre illustration courante de la table HBase consiste à séparer par « : » la famille de colonne et le qualificateur de colonne.
| ROW KEY | TIMESTAMP | COLUMN FAMILY: COLUMN NAME | VALUE (CELL) |
| Clé de la ligne | Date de création ou de mise à jour de la ligne | Famille : colonne | Objet stocké dans la cellule |
Figure 3: représentation courante de la structure logique de la table HBase
La représentation hiérarchique de la structure de la table HBase suivante va vous permettre de garder à l’esprit les liens qui existent entre ces différentes dimensions :
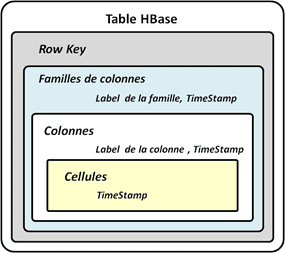 |
| Figure 4 : hiérarchie des dimensions de la table HBase. Comme vous pouvez constater, bien que le TimeStamp soit une dimension distincte, elle est propre à chaque famille de colonne, colonnes et cellules. Par contre, elle est plus utilisée dans les cellules. |
Soit la table HBase suivante :
| Personnel | Contact | |||
| Row Key | Prénom | Age | téléphone | ville |
| 00001 | Juvénal
timestamp: 10/09/2011 13:05:17:09 |
22
timestamp : 10/09/2011 13:05:17:09 |
06 90 98 76 52 timestamp:
10/09/2011 13:05:17:09 |
Douala
timestamp: 10/09/2011 13:05:17:09 |
| 25
timestamp: 20/09/2013 15:00:05:09 |
Lille
timestamp : 20/09/2013 15:00:05:09 |
|||
| Paris
timestamp : 30/10/2016 16:18:50:10 |
||||
| 00002 | Paul
timestamp : 10/09/2011 13:10:05:09 |
30
timestamp : 10/09/2011 13:10:05:09 |
07 90 94 86 52 timestamp:
10/09/2011 13:10:05:09 |
Nancy
timestamp : 10/09/2011 13:10:05:09 |
| 00003 | Jean
timestamp: 12/09/2011 11:30:20:09 |
34
timestamp: 12/09/2011 11:30:20:09 |
06 74 98 76 25
timestamp: 12/09/2011 11:30:20:09 |
Marseille
timestamp: 12/09/2011 11:30:20:09 |
Dans cette table, la Row Key est une colonne triée qui identifie de façon unique chaque « ligne ». La colonne TimeStamp contient des valeurs horodatées qui indiquent les dates auxquelles chaque cellule a été créée. Personnel et Contact sont les familles de colonnes et possèdent respectivement les colonnes Prénom et Age pour Personnel, et téléphone et ville pour Contact. Ces deux familles de colonnes signifient simplement que les colonnes de données Prénom et Age seront sérialisées et persistées sur le même fichier HFile sur le HDFS, téléphone et ville seront sérialisées et persistées sur le même fichier HFile également. Les cellules sont les intersections entre « row key, TimeStamp, famille de colonne et colonne ». Par exemple, la cellule à l’intersection « 00003, 10/09/2011 13:10:05:09, Infos_Contact, ville) contient la valeur « Marseille ». Remarquez que l’horodatage permet d’enregistrer plusieurs versions de la même cellule. Remarquez que les 3 lignes à l’intérieur de la Row Key 00001 sont des versions de la même ligne ; en effet ces 3 lignes représentent le changement d’âge et de ville du contact « Juvenal ». Au lieu de mettre à jour la ligne de row key 00001, et perdre l’historique des états du contact, comme ça aurait été le cas dans un SGBDR de type Oracle ou MySQL, HBase permet de conserver l’historique du contact à l’aide du TimeStamp. A défaut de la représentation précédente, la représentation plate suivante, plus simple est souvent adoptée pour les tables HBase :
| Row Key | Personnel : Prénom | Personnel : Age | Contact : téléphone | Contact : ville |
| 00001 | Juvénal
timestamp: 10/09/2011 13:05:17:09 |
22
timestamp : 10/09/2011 13:05:17:09 |
06 90 98 76 52 timestamp: 10/09/2011 13:05:17:09 | Douala
timestamp: 10/09/2011 13:05:17:09 |
| 25 timestamp : 20/09/2013 15:00:05:09 | Lille
timestamp : 20/09/2013 15:00:05:09 |
|||
| Paris
timestamp : 30/10/2016 16:18:50:10 |
||||
| 00002 | Paul
timestamp: 10/09/2011 13:10:05:09 |
30
timestamp: 10/09/2011 13:10:05:09 |
07 90 94 86 52
timestamp : 10/09/2011 13:10:05:09 |
Nancy
timestamp : 10/09/2011 13:10:05:09 |
| 00003 | Jean
timestamp : 12/09/2011 11:30:20:09 |
34
timestamp: 12/09/2011 11:30:20:09 |
06 74 98 76 25
timestamp : 12/09/2011 11:30:20:09 |
Marseille
timestamp : 12/09/2011 11:30:20:09 |
En dehors de la représentation tabulaire, la table HBase peut se représenter sous forme de schéma multidimensionnelle. Celle-ci est la représentation favorite des développeurs, nous allons expliquer plus bas pourquoi. La représentation d’une table HBase sous un schéma multidimensionnel suit la spécification JSON suivante :
"Row Key 1":
{
"column family 1":
{
"Column 1":
{
"TimeStamp 1": "Cell value",
..................
"TimeStamp N": "Cell value",
}
..............
"Column N":
{
"TimeStamp 1": "Cell value",
..................
"TimeStamp N": "Cell value",
}
}
....................
"column family N":
{
"Column 1":
{
"TimeStamp 1": "Cell value",
..................
"TimeStamp N": "Cell value",
}
..............
"Column N":
{
"TimeStamp 1": "Cell value",
..................
"TimeStamp N": "Cell value",
}
}
}
...............................
"Row Key N":
{
"Column family 1":
{
"Column 1":
{
"TimeStamp 1": "Cell value",
..................
"TimeStamp N": "Cell value",
}
..............
"Column N":
{
"TimeStamp 1": "Cell value",
..................
"TimeStamp N": "Cell value",
}
}
....................
"Column family N":
{
"Column 1":
{
"TimeStamp 1": "Cell value",
..................
"TimeStamp N": "Cell value",
}
..............
"Column N":
{
"TimeStamp 1": "Cell value",
..................
"TimeStamp N": "Cell value",
}
}
}
}
La représentation sous forme de schéma multidimensionnelle de la table HBase de notre exemple donne ceci :
{
"00001":
{
"Personnel":
{
"Prénom":
{
"10/09/2011 13:05:17:09": "Juvénal"
}
"Age":
{
"10/09/2011 13:05:17:09": "22",
"20/09/2013 15:00:05:09": "25"
}
}
"Contact":
{
"Téléphone":
{
"10/09/2011 13:05:17:09": "06 90 98 76 52"
}
"ville d'habitation":
{
"10/09/2011 13:05:17:09": "Douala",
"20/09/2013 15:00:05:09": "Lille",
"30/10/2016 16:18:50:10": "Paris"
}
}
"00002":
{
"Personnel":
{
"Prénom":
{
"10/09/2011 13:10:05:09": "Paul"
}
"Age":
{
"10/09/2011 13:10:05:09": "30"
}
}
"Contact":
{
"Téléphone":
{
"10/09/2011 13:10:05:09": "07 90 94 86 52"
}
"ville d'habitation":
{
"10/09/2011 13:10:05:09": "Nancy",
}
}
}
"00003":
{
"Personnel":
{
"Prénom":
{
"12/09/2011 11:30:20:09": "Jean"
}
"Age":
{
"12/09/2011 11:30:20:09": "34"
}
}
"Contact":
{
"Téléphone":
{
"12/09/2011 11:30:20:09": "06 74 98 76 25"
}
"ville d'habitation":
{
"12/09/2011 11:30:20:09": "Marseille",
}
}
}
}
La représentation sous forme multidimensionnelle permet aux développeurs en fonction de leur langage de programmation, de manipuler la table HBase comme une table de hachage (Ruby), un tableau associatif (PHP), un dictionnaire (Python) ou un objet (Java) qui expose des méthodes via une API. En dehors de la représentation multidimensionnelle, une table HBase peut aussi se représenter sous forme de paires de clés/valeurs. Pour représenter la table sous forme de clé/valeur, vous pouvez utiliser la syntaxe suivante :
{
« Row Key 1 » ->
{« column family 1 »: {« Column 1 »: {« TimeStamp 1 »: « Cell value », « TimeStamp N »: « Cell value »}},
{« Column N »: {« TimeStamp 1 »: « Cell value », « TimeStamp N »: « Cell value »}},
« Column family N »: {« Column 1 »: {« TimeStamp 1 »: « Cell value », « TimeStamp N »: « Cell value »}}, {« Column N »: {« TimeStamp 1 »: « Cell value », « TimeStamp N »: « Cell value »} },
« Row Key N » ->
{« column family 1 »: {« Column 1 »: {« TimeStamp 1 »: « Cell value », « TimeStamp N »: « Cell value »}},
{« Column N »: {« TimeStamp 1 »: « Cell value », « TimeStamp N »: « Cell value »}},
« Column family N »: {« Column 1 »: {« TimeStamp 1 »: « Cell value », « TimeStamp N »: « Cell value »}}, {« Column N »: {« TimeStamp 1 »: « Cell value », « TimeStamp N »: « Cell value »} }
}
La représentation de la table HBase de notre exemple en paires de clés/valeurs donne ceci :
{
« 00001 » ->
{« Personnel »: {« Prénom »: {« 10/09/2011 13:05:17:09 »: « Juvénal »}},
{« Age »: {« 10/09/2011 13:05:17:09 »: « 22 », « 20/09/2013 15:00:05:09 »: « 25 »}},
« Contact »: {« Téléphone »: {« 10/09/2011 13:05:17:09 »: « 06 90 98 76 52 »}},
{« ville d’habitation »: {« 10/09/2011 13:05:17:09 »: « Douala », « 20/09/2013 15:00:05:09 »: « Lille », « 30/10/2016 16:18:50:10 »: « Paris »}}
},
« 00002 » ->
{« Personnel »: {« Prénom »: {« 10/09/2011 13:10:05:09 »: « Paul »}},
{« Age »: {« 10/09/2011 13:10:05:09 »: « 30”}},
« Contact »: {« Téléphone »: {« 10/09/2011 13:10:05:09 »: « 07 90 94 86 52 »}},
{« ville d’habitation »: {« 10/09/2011 13:10:05:09 »: « Nancy » }}
},
« 00003 » ->
{« Personnel »: {« Prénom »: {« 12/09/2011 11:30:20:09 »: « Jean »}},
{« Age »: {« 12/09/2011 11:30:20:09 »: « 34 »}},
« Contact »: {« Téléphone »: {« 12/09/2011 11:30:20:09 »: « 06 74 98 76 25 »}},
{« ville d’habitation »: {« 12/09/2011 11:30:20:09 »: « Marseille »}}
}
}
La connaissance de ces différentes représentations est très importante dans la modélisation de la table HBase. Au même titre que le MCD (Modèle Conceptuel de Données), elles servent d’outil de communication entre les utilisateurs métiers et les développeurs. Généralement la forme tabulaire est très expressive pour les utilisateurs métiers, tandis que les deux autres sont très adaptées pour communiquer avec les développeurs. En fait, la forme de représentation est le premier choix que vous devez faire en matière de modélisation HBase. Attention tout de même à ne pas confondre la représentation de la table HBase avec sa structure interne. Par exemple, le fait de représenter une table HBase sous forme de clé/valeur ne signifie pas qu’HBase fonctionne comme un SGBD clé/valeurs. C’est juste une représentation. Maintenant que vous avez compris les concepts de base de HBase, nous allons vous emmener dans son architecture et son fonctionnement interne.
2. ARCHITECTURE ET FONCTIONNEMENT DU HBASE
HBase est un SGBD distribué et en tant que tel, il s’installe sur un cluster d’ordinateurs. Comme Hadoop, HBase s’installe sur un cluster en architecture Maître/Esclave. Dans la terminologie HBase, le nœud maître s’appelle le HMaster, et les nœuds esclaves s’appellent les RegionsServers. Le stockage des données est distribué sur les RegionsServers qui sont gérés par le HMaster. Le HMaster gère les métadonnées des tables HBase et coordonne l’exécution des activités des RegionsServers, tandis que les RegionsServers effectuent les opérations de lecture/écriture de données dans le cluster. La gestion du volume de données se fait par l’ajout des RegionsServers supplémentaires dans le cluster. La figure ci-après illustre l’architecture d’un cluster HBase.
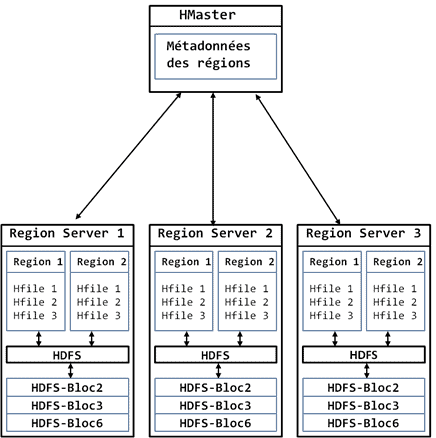
Comme vous le savez déjà, les tables HBase sont persistées sur le disque sous forme de fichiers HDFS appelés HFiles. Chaque HFile contient les données d’une et une seule famille de colonnes. Toutes les lignes de la table sont identifiées de façon unique à l’aide d’une valeur de la row key. Etant donné que la table fait office de base de données, pour une application métier donnée, toutes les données sont stockées dans la seule table HBase, qui pourra alors rapidement contenir des milliards de lignes, chiffrant sa taille en Téra octets voir Péta-octets. Cette taille phénoménale rend impossible le stockage de la table sur une seule machine. Pour résoudre ce problème, les tables HBase sont divisées en partitions appelées « régions » qui sont réparties entre les nœuds RegionsServers pour le stockage. La taille de chaque région peut être paramétrée dans un fichier de configuration hbase-site.xml. Lorsque la taille d’une région dépasse la taille maximale que vous avez définie dans le fichier de configuration, la région se partitionne automatiquement en deux. La région est une partition de la table triée par valeurs de la row key. La table étant déjà physiquement partitionné en HFiles, une région sera physiquement persistée sous forme d’un ou plusieurs HFiles. Les régions forment l’unité de stockage en HBase et sont la clé de la distribution du stockage et de la scalabilité du cluster HBase. La figure suivante illustre la façon dont HBase partitionne les tables en régions.

Les régions sont distribuées sur le cluster de façon aléatoire et chaque nœud RegionsServer peut stocker une ou plusieurs régions. Les régions sont répliquées entre les nœuds de façon à maintenir la disponibilité du cluster en cas de panne. Lors de l’ajout d’une ligne existante dans une table (nouvelle version de la ligne), HBase retrouve la région contenant la valeur de la row key de la ligne et l’insère dans cette région. Pour retrouver la région contenant la row key, HBase utilise une table de catalogue spéciale appelée « hbase:META ». Cette table contient la liste des RegionsServers disponibles, et la liste des intervalles de valeurs de row key pour chaque région de table. Elle est stockée dans un composant de l’écosystème Hadoop appelé ZooKeeper, qui tourne sur un cluster différent du cluster sur lequel est installé HBase. ZooKeeper est nécessaire parce qu’à la différence d’Hadoop où la communication entre le client et le cluster se fait à l’intermédiaire du nœud de référence, dans HBase, le client communique directement avec les nœuds RegionsServer sans passer par le HMaster. Le client n’a donc aucun moyen de connaître dans quel RegionsServer sont situées les données dont il a besoin. Lorsqu’un client fait une requête sur une row key précise, ZooKeeper pointe vers la table hbase : META pour récupérer les informations de la région contenant la row key, ensuite ZooKeeper renvoie cette information au client, qui va alors directement s’adresser au RegionsServer contenant la région. Finalement, la RegionsServer va traiter la requête et renvoyer au client les données de la row key. La figure ci-après illustre le fonctionnement d’HBase lors d’une opération de lecture de données.

|
Ce mode de fonctionnement est effectif uniquement à partir de la version 0.96 d’HBase. Antérieurement à cette version, HBase utilisait 2 tables de catalogue pour gérer les références de régions : .META. et –ROOT-. .META. contenait la liste des RegionsServers disponibles, la liste des partitions dans chaque RegionsServer et leurs valeurs de row key. .META. était partitionnée en régions et lorsqu’un client envoyait une requête sur une row key précise, la requête n’accédait pas directement à la table .META., mais elle accédait à la table -ROOT-. La table -ROOT- était gérée par ZooKeeper et pointait vers la liste des régions .META. À partir de la version 0.96, la table –ROOT- a été supprimée et la table .META. a été remplacée par la table hbase:META actuelle. La table hbase:META n’est désormais plus gérée par HBase, mais par ZooKeeper. |
3. UTILISATION DE HBASE
A ce stade, vous avez compris les principes de fonctionnement de HBase. Vous avez compris la différence entre les bases de données relationnelles et les tables HBase. Vous êtes également conscient maintenant de la différence entre HBase et un SGBDR. Dans cette partie, nous allons vous aider à développer des compétences opérationnelles sur l’exploitation d’un cluster HBase.
3.1. Règles de modélisation d’une table HBase
Tout comme dans l’approche relationnelle la première étape consiste à modéliser la base de données à travers un MCD, la première étape dans tout projet HBase est la modélisation de la table HBase. Nous allons vous fournir ici les règles de bonnes conception et modélisation d’une table HBase. Comme nous l’avons dit plus haut, la modélisation en HBase consiste à concevoir et implémenter des tables HBase dans le but d’y exécuter des requêtes distribuées. La modélisation des bases de données relationnelles se fait à l’aide d’un MCD qui sera transformé en schéma relationnel à l’aide d’un ensemble de règles standardisées appelées Formes Normales (les 12 Formes Normales). Lorsqu’on modélise une base de données relationnelle, le but est de réduire la redondance et d’assurer la cohérence des données. Les Formes Normales assurent que les schémas de base de données qui seront modélisés minimiseront les redondances et maximiseront la cohérence de la base. Dans un environnement distribué, on ne peut pas se permettre de minimiser la redondance des données, puisque c’est la redondance qui est la clé de la haute disponibilité et de la tolérance aux pannes du cluster ; au contraire il faut la maximiser pour assurer une répartition équilibrée des données dans le cluster. Dans un SGBD distribué en général et dans HBase en particulier, le but de la modélisation est d’assurer le partitionnement des données en blocs qui vont être distribués dans le cluster de façon indépendantes de manière à garantir l’accès rapide à ces blocs par les requêtes. A la différence des règles de modélisation des Bases de Données Relationnelles qui font l’objet de standards approuvés et validés par des organismes comme l’OMG (Object Management Group) , ou l’ISO, les règles de modélisation en environnement distribué, précisément en HBase proviennent plus des « Best practices », c’est-à-dire des pratiques éprouvées sur le terrain que de standards. Ces « Best Practices » ne s’appuient pas sur des expérimentations, mais sur les principes du stockage et du traitement de données en environnement distribué.
Préalablement à l’application des règles de modélisation comme les formes normales, le concepteur utilise un ensemble de questions pour le guider dans la conception de sa base de données. Dans le cas d’une base de données relationnelle, ces questions sont les suivantes : quelles sont les tables de notre base de données ? Quelles sont les clés primaires ? Quelles sont les associations qui existent entre les tables ? Ainsi de suite. Idem, préalablement à l’application des « Best practices », vous devez répondre aux questions suivantes pour modéliser une table HBase :
– quelle est la structure des valeurs de la row key ?
– Combien de familles de colonnes la table doit-elle avoir ?
– Quelles données vont dans quelle famille de colonnes ?
– Combien de colonnes y’a t-il dans chaque famille ?
– Quel est le label ou titre de chaque colonne ?
– Quelles données seront stockées dans les cellules ?
– combien de versions de chaque cellule HBase devra t’il historiser ?
Une fois que vous avez répondu à ces questions, vous pouvez utiliser ce guide de « best practices » pour assurer la modélisation optimale de la ou des tables. Il y’en 5 principales :
– Regroupez les colonnes utilisées selon le même schéma dans la même famille de colonnes. les colonnes appartenant à la même famille de colonnes sont persistés sur le même fichier HFile dans le HDFS. Par conséquent, les colonnes qui sont utilisées suivant un même schéma doivent être regroupées dans la même famille de colonnes. Lorsque nous parlons de colonnes utilisées selon le même schéma, nous faisons référence aux colonnes qui sont utilisées au même moment, ou dont la modification de l’une entraîne la modification de l’autre. Par exemple supposons que nous avons les colonnes prix total, prix unitaire, quantité, une modification de la colonne prix total passe toujours par une modification de la colonne prix unitaire et quantité. Par conséquent, il serait optimal de regrouper ces 3 colonnes dans la même famille de colonnes ;
– Essayer autant que faire se peut de limiter à 10 ou 15 le nombre de familles de colonnes par table. A cause du fait que chaque famille de colonne = 1 fichier HFile différent, lorsque HBase veut lire une ligne de données particulière, il effectue une jointure de tous les HFiles des familles de colonnes avant d’identifier la ligne dans chaque fichier à l’aide de sa row key. Donc plus, il y’a de HFiles, plus il faut de temps pour les fusionner afin de lire les données ;
– Donnez le nom de toutes les colonnes à la création de la table même si les colonnes elles-mêmes n’existent pas encore. Ces noms seront enregistrés par HBase sous forme de métadonnées. Lorsque les colonnes seront effectivement créées par le développeur, il s’appuiera sur ces métadonnées pour les nommer. De plus, étant donné que ces métadonnées sont stockées dans la table, elles occupent de l’espace disque, par conséquent vous devriez limiter la longueur du nom des colonnes pour gagner en espace disque ;
– Privilégiez une structure composite pour les valeurs de la row key. En effet, l’accès aux données de la table HBase se fait par des opérations de lecture/écriture à partir de la row key. Par conséquent, la structure des valeurs de la row key doit s’accommoder à tous les scénarios d’accès à la table envisageables. Une structure composée de plusieurs types de valeurs concaténées est donc la plus appropriée pour couvrir la majorité des cas. Dans tous les cas, évitez le schéma de la clé à valeur auto-incrémentée, type 1, 2, 3… comme c’est souvent le cas dans la modélisation de la clé primaire en base de données relationnelle. Voici 3 modèles de clé composite pour la row key : « valeur aléatoire » + valeur auto-incrémentée, utilisation des valeurs d’une colonne particulière comme valeurs de la row key, ou simplement valeurs aléatoires comme valeurs de la row key. Par exemple : foo0001, a-foo1, xhek23eh ;
– Dé-normalisez au maximum les tables que vous modélisez. En effet, la priorité de HBase c’est de distribuer le stockage des données sur les nœuds d’un cluster et d’en faciliter l’accès. Pour une distribution efficace, il faut que les partitions entretiennent le moins de liens possibles. Adoptez donc un esprit de modélisation qui favorise le moins de normalisation possible, c’est-à-dire exactement l’inverse de ce qui se fait en modélisation relationnelle. De plus, la dénormalisation dans un contexte distribué favorise une performance élevée des requêtes ;
En utilisant ce guide de questions et de règles, vous développerez des tables qui seront efficacement partitionnés, distribués dans le cluster et rapide à accéder. Nous allons maintenant passer à la deuxième étape, l’exploitation de la table.
3.2. Exploitation d’une table HBase
Une fois que la table a été modélisée et implémentée, vous pouvez l’utiliser. Pour interagir avec HBase et effectuer des opérations comme la création de table, la lecture ou l’écriture de données, vous passez par un client HBase. Tout comme Hadoop, HBase a été développé en Java. Il fournit des interfaces de programmation d’application (API) natives Java pour la programmation des tâches de création et de manipulation des tables. Ces API se sont les classes JAVA HTableInterface ou HTable. Elles fournissent les méthodes nécessaires à la manipulation, la configuration d’HBase et l’exploitation des tables qui y sont implémentées.
Dans les SGBDR, pour interagir avec la Base de données, le SGBDR utilise le SQL et celui-ci sert à la fois de langage de définition de la structure de la base de données et d’exploitation de la base de données. Le SQL fournit un ensemble d’opérations et ce sont ces opérations que l’analyste utilise pour manipuler sa base de données. 2 catégories d’opérations y sont fournies : les opérations de définition de la base de données (le CRUD – CREATE, INSERT, UPDATE, DELETE) et les opérations d’interrogation de la base de données (SELECT). L’utilisateur définit une requête à l’aide d’une ou des deux catégories de ces opérations et elle est soumise au SGBDR pour traitement. Il en est de même avec HBase. HBase fournit une série d’opérations pour interagir avec les tables HBase. Ces opérations peuvent être exploitées en masse par le MapReduce. Ces opérations sont au nombre de 4 :
– Get : équivalent à l’opération SQL SELECT, cette opération permet de renvoyer les valeurs soit d’une colonne soit d’une famille de colonnes soit alors des versions des valeurs de cellule pour une ligne spécifiée. Si le Get est utilisé pour lire les valeurs d’une famille de colonne, donc des données du même HFile, alors HBase n’effectuera pas de jointure de HFiles. La syntaxe de cette commande est la suivante :
get ‘table name’, ‘rowkey_value’, {COLUMN ⇒ [‘column_family:column_name’, ……, ‘column_family:column_name’], VERSIONS => …}
Exemple : get Customers’, ‘CC09877’, {COLUMN ⇒ [‘personal:customer_name’, ‘public: ‘enterprise’], VERSIONS => 10}.
Cette requête porte sur la table Customers et extrait les valeurs des colonnes customer_name et enterprise pour la Row Key de valeur CC09877, elle y extrait les 10 premières versions de la row_key ;
– Put : équivalent à un INSERT en SQL, cette opération ajoute une nouvelle ligne dans la table si cette ligne n’existe pas (c’est-à-dire que la valeur de clé n’existe pas dans la table) ou ajoute une nouvelle version de la même ligne si elle existe déjà dans la table. Comme avec le GET, le PUT peut se limiter à ajouter une ligne dans une colonne ou une famille de colonnes spécifiques. La syntaxe de cette commande est la suivante :
Put ‘table_name’, ‘rowKey_value’, ‘colum_family:column_name’, ‘value’,… ‘colum_family:column_name’, ‘value’
Exemple : ajouter à la table Customers une nouvelle version de la rowkey ‘CC09877’, les valeurs respectives ‘juvénal’ et ‘CAPGEMINI’ aux colonnes ‘personal:customer_name’, ‘public: ‘enterprise’. Cela donne la requête suivante :
Put ‘customers’, ‘CC09877’, ‘personal:customer_name’, ‘juvénal’, ‘public: ‘enterprise’, ‘CAPGEMINI’ ;
– Scan : cette opération permet d’itérer sur plusieurs lignes pour récupérer les lignes de familles de colonnes, colonnes ou cellules pour des clés spécifiques. La syntaxe de cette commande est la suivante :
scan ‘< TABLE>’, {COLUMNS => [ »,…, »], VERSIONS => , FILTER => <critère filtre>, LIMIT = <nbre_de_valeurs_renvoyées> …}
Exemple : scan ‘customers, {COLUMNS => [‘personal:customer_name’, ‘public: enterprise’], VERSIONS => 10, FILTER => « PrefixFilter(‘CC09877’) » }. Cette requête renvoie les données dont les rowKeys sont préfixées « CC ». Vous pouvez transférer les résultats renvoyés par la requête en utilisant la commande shell suivante :
echo « commande hbase shell » | hbase shell > fichier.txt
par exemple, on peut transférer les résultats de notre requête en la re-écrivant de la façon suivante :
echo » scan ‘customers, {COLUMNS => [‘personal:customer_name’, ‘public: enterprise’], VERSIONS => 10, FILTER => « PrefixFilter(‘CC09877’) » } => results.txt ;
– Delete : A l’instar du DELETE en SQL, cette opération supprime une ou plusieurs lignes spécifiques, colonnes, familles de colonnes ou cellules. En réalité, la suppression ne se fait pas au moment où la requête est envoyée, au contraire, HBase crée des marqueurs sur chaque valeur à supprimer et celles ci sont supprimées massivement lorsqu’HBase effectue un compactage de la table. La syntaxe pour cette commande est la suivante :
delete ‘’, ‘’, ‘’, ‘’. Exemple: delete customers ‘CC09877’, ‘personal: customer_name’, 1209201600002345. Cette commande supprime la version 1209201600002345 de la row key CC09877 pour la colonne customer_name ;
|
Les développeurs peuvent utiliser les interfaces HTableInterface ou HTable pour écrire en Java des programmes qui implémente les commandes GET, PUT, SCAN et DELETE. |
Toutes ces opérations peuvent se programmer de façon massivement parallèle à l’aide du MapReduce, et donc par ricochet l’utilisateur non technique peut utiliser un langage d’abstraction comme le HiveQL ou le Pig Latin pour créer et manipuler les tables HBase. Apache a récemment intégrer dans Hive une classe HBaseStorageHandler qui permet de mapper les tables HBase à Hive. Vous pouvez ainsi utiliser une opération CREATE TABLE dans HiveQL pour créer une table dans HBase, SELECT pour renvoyer les valeurs, INSERT pour insérer les valeurs dans la table HBase et ainsi de suite. supposons que nous voulons créer une table HBase à partir d’un script HiveQL, la requête serait la suivante :
CREATE TABLE IF NOT EXISTS Clients(
id_client STRING,
concat(Nom_client,’ ‘, prenom_client) Noms_client
datediff(date_naissance, CURRENT_DATE()) Age_client,
Substr(genre, 1, 1) genre,
Qantité * Prix_unitaire Vente)
STORED BY ‘org.apache.hadoop.hive.HBaseStorageHandler’
WITH SERDEPROPERTIES (“hbase.columns.mapping” = “id_client:key, personal:customer_name, personal:customer_age, personal:customer_gender, product:sales)
TBLPROPERTIES (“hbase.table.name” = “Customers”);
Dans la requête, nous créons dans HBase, une table appelée ‘customers’, possédant 2 familles de colonnes : ‘personnal’ et ‘product’. Les valeurs de la row key de la table sont les valeurs de la colonne id_client, et la famille ‘personnal’ contient les colonnes Noms_client (avec pour label customer_name), Age_client (avec pour label ‘customer_age’), genre (avec pour label ‘customer_age’). Après avoir créé et référencé la table HBase avec l’instruction CREATE TABLE, vous pouvez l’utiliser normalement comme si vous étiez en train de faire du HiveQL classique, à la seule différence que chaque instruction est retranscrite en son équivalent GET, PUT, SCAN ou DELETE en HBase. Par exemple, vous pouvez utiliser une instruction INSERT pour charger votre table HBase des données d’entrée stockées dans le HDFS.
FROM Clients INSERT INTO TABLE Customers
SELECT Clients.* ;
Vous pouvez également utiliser le SELECT pour envoyer des requêtes de lecture spécifiques à HBase.
SELECT sum(vente) FROM Clients WHERE age_client BETWEEN 25 AND 30 GROUP BY genre ;
Voilà, maintenant vous savez comment utiliser HBase. Vous pouvez vous inspirer des modèles de scripts et des exemples que nous avons fournis ici pour commencer à écrire vos propres programmes HBase.
3.3. Mapping d’une Base de Données Relationnelle vers une table HBase
Nous savons qu’en tant que professionnel ou étudiant, vous avez l’habitude de travailler avec les Bases de Données relationnelles. Pratiquement toutes les entreprises utilisent encore les bases relationnelles. Avec la transition Numérique en cours, elles seront forcées de migrer certaines de leurs bases de données relationnelles vers des SGBD NoSQL. Vous serez donc surement emmenés à travailler sur des projets de migration de données, des bases relationnelles vers les bases NoSQL en général, et vers les tables HBase en particulier. D’après notre expérience personnelle, les projets de migration des bases de données relationnelles vers HBase sont de plus en plus courants. Dans ce point, notre objectif est de vous donner les clés pour migrer efficacement une base de données relationnelle vers une table HBase. Nous avons identifié 3 clés dont l’application garantit la migration réussie du relationnel vers HBase :
– Gardez déjà à l’esprit que le monde du NoSQL représente tout d’abord un changement de paradigme, c’est comme si vous cessez de vivre dans une démocratie et subitement intégrez une monarchie. Ce n’est pas tant les principes ou les concepts qui diffèrent du SQL au NoSQL, mais c’est la façon de penser. Ainsi, migrer une base relationnelle vers une base non relationnelle va vous demander de penser différemment que ce que vous avez toujours eu l’habitude de penser ;
– La priorité d’une base de données relationnelle c’est la cohérence de la base de données et l’intégrité des transactions qui y sont effectuées. La priorité d’une table HBase c’est la distribution du stockage et l’accès rapide aux partitions distribuées. Ainsi, à cause de ces priorités divergentes, si vous devez migrer une base de données relationnelle vers une table NoSQL, de prime abord, ne le faites pas ! Mais si vraiment vous êtes dans l’obligation de le faire, alors reconstruisez votre base en tenant compte des priorités de HBase, c’est-à-dire la facilité de distribution et la rapidité d’accès ;
– Si vous devez absolument migrer votre base, alors évaluez les inconvénients associés à la dénormalisation de votre base de données ; si ceux-ci sont acceptables, du moins dans le moyen terme, alors essayer d’obtenir des tables HBase qui respectent les règles de modélisation que nous avons énoncées plus haut ;
Voilà, en tenant compte des conseils de ce petit guide, vous pourrez prendre des décisions adéquates quant à une éventuelle migration de base relationnelle vers une ou plusieurs tables HBase. Nous allons également aborder la migration de Phoenix à HBase.
3.4. Phoenix et HBase
Phoenix est une couche SQL installée au-dessus de HBase pour l’exécution des requêtes SQL sur les données stockées dans des tables HBase. Phoenix est un autre moyen pour exploiter HBase. Nous dirions même qu’il est le plus simple et le plus performant car il s’appuie sur le SQL, que vous connaissez déjà. Si nous revenons sur l’étude de Phoenix c’est à cause de sa progression dans le marché, il est de plus en plus adopté comme interface d’utilisation d’HBase à cause de la transparence qu’il offre aux utilisateurs métiers et l’utilisation du SQL. La figure ci-après illustre l’architecture simplifiée de HBase et le positionnement de Phoenix dans l’architecture de HBase.

Comme la figure le montre, Phoenix est installé au niveau du client HBase d’une part, c’est-à-dire au niveau de l’interface HTableInterface. D’autre part, au niveau des RegionsServers. Ainsi, Phoenix ne distribue pas lui-même les données, il n’exécute pas non plus les requêtes, il permet aux utilisateurs d’écrire des requêtes SQL à la place des commandes GET, PUT, SCAN, DELETE (au niveau du client), les compilent et les exécutent directement au niveau des RegionsServers. La différence par rapports aux commandes classiques est qu’une fois compilées, ces requêtes sont exécutées sur les régions de la table HBase sans être transformées en fonctions MapReduce. Par contre, c’est HBase qui s’occupe des aspects distribués du traitement. C’est pour cette raison que dans la communauté open source, on dit de Phoenix qu’il est le « SQL Skin for HBase » (la peau SQL de HBase). La compilation effectuée par Phoenix aboutit à des performances de l’ordre de la milliseconde en fonction du volume de données traité. En filigrane, on pourrait dire que Phoenix essaye de fonctionner comme un moteur SQL MPP. Phoenix supporte aussi bien la création de table HBase que le mapping d’une table HBase existante. La spécification SQL de Phoenix est conforme aux différentes normes SQL. Rendez-vous sur le site officiel d’Apache Phoenix pour plus de détail.
CONCLUSION DU TUTORIEL
Les exigences de volumétrie de données de l’ère Numérique forcent les entreprises à changer d’approche de stockage de données et d’utiliser le HDFS. Stocker les données dans le HDFS parce que c’est un système de fichier distribué c’est une chose, mais gérer les données sur un environnement distribué c’est autre chose. Les SGBD NoSQL ont pour objectif d’assurer la gestion des données stockées sur un cluster à travers un système de fichier distribué. HBase est l’un d’entre eux. A cause de sa flexibilité et du large nombre de cas d’usages pour lesquels il est adapté, HBase est l’un des SGBD NoSQL qui prend de plus en plus d’ampleur sur le marché. Avec les limites rencontrées avec les SGBDR, les entreprises sont de plus en plus soit en train de migrer leurs bases de données relationnelles vers HBase, soit sont en train de l’envisager. Dans ce tutoriel, nous vous avons emmené à développer une compréhension claire des principes de fonctionnement de HBase, de la façon dont HBase gère les données, et nous vous avons également aidé à développer des compétences opérationnelles à la fois sur la modélisation des tables HBase que sur leur exploitation. Il ressort globalement du tutoriel que HBase est une nouvelle catégorie de SGBD qui donne accès à temps réel aux données stockées sur le HDFS. Son but est d’assurer la distribution du stockage des données à travers le cluster et de fournir un temps d’accès rapide à ces données lors des requêtes. Il peut être combiné au MapReduce pour le traitement massivement parallèle. Il s’appuie sur ZooKeeper pour l’exploitation des données et s’interface très bien avec Hive, et Phoenix. Nous avons introduit beaucoup de concepts dans ce tutoriel. Nous vous recommandons de consolider vos acquis de compétence à travers le mini-quizz d’étude ci-après.
Ce tutoriel est extrait de l’ouvrage « Maîtrisez l’utilisation de l’écosystème Hadoop ». HBase est l’une des technologies phare du Big Data. Si vous souhaitez progresser dans le développement de vos compétences sur les technologies de l’écosystème Hadoop, n’hésitez pas à vous procurer l’ouvrage en cliquant sur le lien suivant : Maîtrisez l’utilisation de l’écosystème Hadoop. Vous y développerez des compétences sur 18 technologies clés de l’écosystème Hadoop, notamment Spark, Hive, Pig, Impala, ElasticSearch, HBase, Lucene, HAWQ, MapReduce, Mahout, HAMA, TEZ, Phoenix, YARN, ZooKeeper, Storm, Oozie, et Sqoop. A la fin de sa lecture, vous serez également capable de choisir les solutions techniques adaptées à vos problèmes de Big Data.
Ressources complémentaires
Si vous souhaitez aller plus loin dans l’apprentissage de HBase et plus généralement sur l’utilisation des SGBD NoSQL pour valoriser vos données, n’hésitez pas à consulter les liens suivants.
- Consultez le site d’Hadoop, vous y trouverez les dernières mises à jour concernant ses différents composants, notamment le HDFS, YARN, et le MapReduce : https://hadoop.apache.org/
- pour avoir accès à la documentation officielle de HBase, rendez-vous sur le site suivant : https://hbase.apache.org/
- Vous pouvez également télécharger gratuitement le livre numérique que nous avons rédigé sur ElasticSearch, un autre SGBD NoSQL, spécialisé dans l’indexation et la recherche de contenu. Cliquez ici pour vous le procurer : https://www.data-transitionnumerique.com/extrait-ecosystme-hadoop/
- Apache Cassandra est également un SGBD NoSQL orienté colonne au même titre que HBase. Il peut même être envisagé comme une alternative à HBase : http://cassandra.apache.org/
- Apache Accumulo est également un SGBD NoSQL distribué de large créée par la NSA pour la gestion de larges volumes de données. Il est aujourd’hui Open source et il peut être intéressant à envisager pour votre projet Big Data : https://accumulo.apache.org/
Lectures recommandées
Pour vous aider à avancer dans vos projets Big Data ou simplement à monter en compétence que ce soit sur HBase, ou n’importe quelle technologie de l’écosystème Hadoop, nous vous recommandons les excellents ouvrages suivants :

Big Data et Machine Learning, 3ème édition, l’excellent livre de Dunod qui fournit un très bon panorama des technologies de l’écosystème Hadoop.

Hadoop, The Definitive Guide, 4ème édition, l’excellent ouvrage de Tom White des éditions Oreilly. Cet ouvrage couvre en profondeur HBase et les technologies principales de l’écosystème Hadoop. Il faut noter que Tom White travaille chez Cloudera et est lui-même très impliqué dans le développement des technologies Hadoop. Le seul défaut c’est que l’ouvrage est en anglais

Maîtrisez l’utilisation des technologies Hadoop“, l’ouvrage duquel est extrait ce tutoriel HBase et le deuxième livre du projet DTN. En plus d’HBase, il contient de nombreux tutoriels pas-à-pas qui vous permettront de façon professionnelle 18 technologies centrales de l’écosystème Hadoop dans vos projet Big Data



On peut dire que l’exploitation de HBase se fait seulement A travers Hive, l’API et phoenix ?seulement?
Bonjour Marwa,
non pas seulement. Vous pouvez également utiliser l’API HTableInterface, qui contient les classes JAVA qui vont vous permettre d’interroger les tables HBase par programmation. Vous pouvez également utiliser la ligne de commande HBase et exécuter les commandes shell/bash « scan », « put », « delete », etc…
Cela répond t’il à votre question ?
Oui merci
Pourquoi on aurait besoin des SGBD NoSQL le temps que hadoop fournit son propre système de stockage HDFS?
Bonjour Wassim,
le HDFS n’est pas un SGBD, c’est juste un système de fichier distribué. C’est un peu comme dire : « pourquoi utiliser MySQL alors que le serveur fournit déjà son propre disque dur ».
J’espère qu’à partir de ce rapprochement, tu comprends la différence entre le SGBD et le système de fichier du disque dur.
Bonne journée,
Juvénal
j »aime bcp cette article c’est tres utile merciii
Merci beaucoup pour votre commentaire Elhaddad, c’est très encourageant !